Diffusion Models Beat GANs on Image Synthesis

원문 링크: [paper]
저자: Prafulla Dhariwal, Alex Nichol
[OpenAI]
[Github]
[1 Jun 2021]
번역자: Zhenghui Piao
DDPM은 Unconditional Model입니다. 예를 들어서 ‘흰색 이미지 배경인 시계 생성해줘’와 같은 조건부 명령을 내릴 수 없습니다. 그렇기 때문에 Conditional 생성을 위해서 알아야 하는 논문 중 하나인 Classifier Guidance에 대해서 설명해보도록 하겠습니다.
1. Motivation
- (1) GAN 모델은 높은 생성 품질을 달성할 수 있지만, 이는 다양성을 희생하는 대가로 이루어집니다. 또한, GAN 모델은 정교한 매개변수 선택이 필요하며, 이를 잘못 다루면 쉽게 붕괴될 수 있습니다.
- (2) 현재 GAN 모델의 구조에 대한 연구가 풍부하며, 비교적 완전한 실험적 탐구 결과가 있습니다.
- (3) 확산 모델은 이미 고품질의 이미지를 생성할 수 있음이 입증되었으며, GAN에 비해 표본 분포를 더 잘 커버할 수 있습니다. 그러나 확산 모델 구조에 대한 연구는 상대적으로 적으며, 확산 모델은 여전히 개선될 가능성이 있습니다.
2. Contribution
- (1) GAN 실험에서 영감을 얻어 확산 모델을 대규모로 분해 실험하였고, 더 나은 구조를 찾았습니다.
- (2) ImageNet 생성 작업에서 최신 BigGAN을 능가하여 ‘128×128’ 이미지에서 FID가 2.97, ‘256×256’ 이미지에서 FID가 4.59, ‘512×512’ 이미지에서 FID가 7.72에 이르렀습니다. 동시에, 확산 모델은 BigGAN보다 데이터 분포와 더 잘 일치했습니다.
3. Introduction to Diffusion Model
- Forward Process: 이미지 $(X_0)$ 가 완전한 Gaussian Noise $(X_T)$ 가 될 때까지 Gaussian Noise를 점직적으로 추가하는 Markov Process
- Reverse Process: Gaussian Noise $(X_T)$ 에서 점진적으로 Gaussian Noise를 제거하여 이미지 $(X_0)$ 를 복원하는 Markov Process

3.1 Forward Process
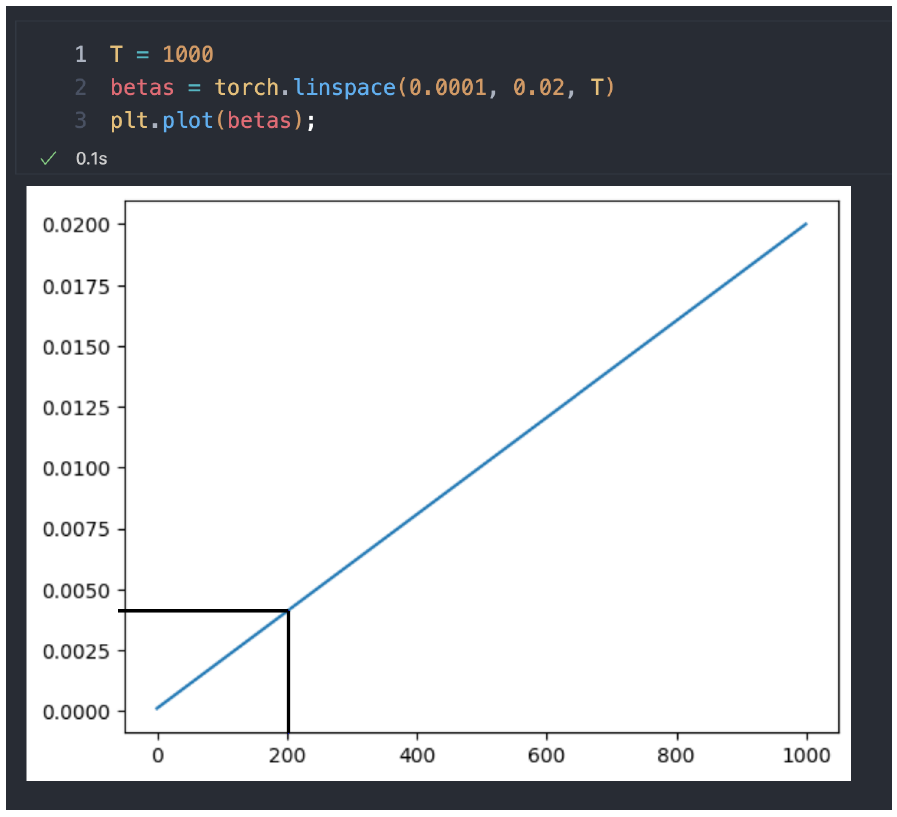
사전 정의 된 Timestep 만큼 T번 Forward Process를 수행하면 이미지 Isotropic Gaussian (완전한 노이즈)로 수렴해야 합니다. 이를 만족하기 위해서 Noise Schedule을 정의, 즉 $\beta$ 값의 집합입니다.
현 시점이 200일 때 한번 Forward Process 적용:
-
- 이미지 픽셀값에 $\sqrt{1-\beta_{200}}$ 를 Element wise multiplication
-
- 이미지와 같은 차원의 랜덤 가우시안에서 샘플 추출
-
- 랜덤 가우시안과 $\sqrt{\beta_{200}}$ 를 Element wise multiplication
-
- 더해주면 201 시점의 노이즈가 더 추가된 이미지 생성 DDPM 논문에서는 $T$ = 1000, $\beta_0$ = 0.0001, $\beta_{1000}$ = 0.02로 정의
3.2 Reverse Process
DDPM에서는 Reverse Process의 분산을 고정, 평균을 학습합니다.
4. Model Architecture
본 논문에서 사용된 기본 모델은 참고문헌 DDPM에 언급된 UNet에 단일 헤드 글로벌 어텐션 모듈을 추가한 구조입니다. 이 기반 위에서 기본 구조의 다른 구성 요소를 수정하여 모델 성능에 미치는 영향을 조사했으며, FID를 평가 지표로 사용하여 ImageNet 128×128에서 소거 실험을 진행했고, 배치 크기는 256으로 설정했습니다.
구체적으로는, 네트워크의 너비나 깊이(모델 전체 크기를 일정하게 유지), 어텐션 헤드의 수, 어텐션의 해상도, BigGAN의 잔차 블록을 사용한 UNet 중의 업샘플링과 다운샘플링 활성화, 잔차 연결의 가중치 조정 등을 평가했습니다.
최종 결과는 표 1과 같습니다.
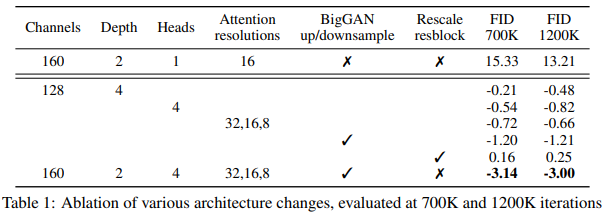
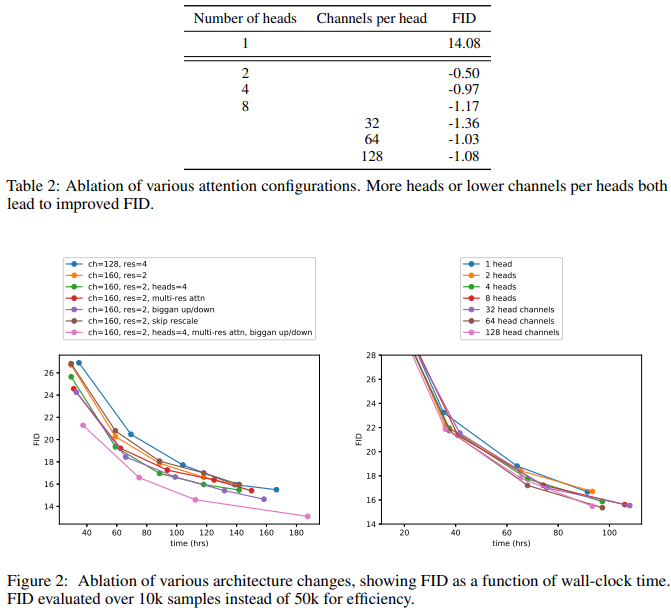
네트워크의 너비를 넓히거나 깊이를 더하는 것이 모델 성능을 향상시키는 데 도움이 된다는 것을 발견할 수 있습니다. 하지만 보고된 최상의 효과는 이러한 조정을 하지 않았습니다; 동시에, 어텐션 헤드 수를 늘리고, 단일 헤드 단일 해상도만 사용하는 대신 다중 해상도 조합의 어텐션 모듈을 사용하는 것이 모델 성능을 향상시키는 데 더 도움이 됩니다. BigGAN의 업샘플링과 다운샘플링 잔차 블록도 모델 성능 향상에 기여하지만, 잔차 연결 강도를 변경하는 것은 긍정적인 효과가 없었습니다. 이와 동시에, 저자는 더 적은 수의 채널을 사용하는 어텐션이 성능 향상에 더 도움이 된다는 것을 입증했습니다.
또한, 저자는 적응적 그룹 정규화(Adaptive Group Normalization)라는 방법을 제안하여 정규화 작업을 수행하였습니다. 이 방법은 그룹 정규화에 대한 개선입니다: 위의 공식에서 $h$ 는 잔차 블록 활성 함수의 출력이고, $y$ 는 시간 단계에 대한 선형 층과 나중에 사용되는 클래스 정보의 임베딩입니다. 그룹 정규화는 입력의 채널 방향으로 그룹을 나누어 정규화하는 방법으로, 지역적인 LayerNorm으로 이해할 수 있습니다:
여기서 진행된 Ablation 실험은 상대적으로 적었으며, 그들의 AdaGN과 하나의 베이스라인의 효과만을 비교했습니다.

5. Classifier Guidance
저자는 현재 고품질 GAN 네트워크가 종종 이미지 생성에 클래스 정보를 보조적으로 사용하는 원리에 영감을 받아, 분류 모델을 통해 이미지를 생성하는 알고리즘을 개발했습니다. 이 알고리즘의 아이디어는, 다른 시점의 이미지 $X_t$ 를 사용하여 분류기를 훈련시키고, 이후에 분류기가 $X_t$ 의 그래디언트 정보를 사용하여 확산 모델의 생성을 안내합니다.

수정해야 할 부분이나 의문이 있으신 분들은 메일로 연락 주시길 바랍니다.