Scalable Diffusion Models with Transformers

원문 링크: [paper]
저자: William Peebles, Saining Xie
[UC Berkeley, New York University]
[Github]
[2 Mar 2023]
번역자: Zhenghui Piao
새로운 확산 모델 연구에서는 전통적인 U-Net 구조를 잠재 패치에서 작동하는 트랜스포머로 대체하여 잠재 확산 모델 학습에 초점을 맞추었다. 이 연구에서는 Gflops를 기준으로 순방향 경로의 복잡성을 분석하여 확산 트랜스포머(DiT)의 확장 가능성을 평가했다. 트랜스포머의 깊이와 너비를 증가시키거나 입력 토큰 수를 늘릴수록 Gflops 수치가 높아지고, 이는 일관되게 낮은 FID 값을 나타내는 경향이 있음을 발견했다. 이와 같은 우수한 확장성을 갖춘 DiT-XL/2 모델은 클래스 조건부 ImageNet 512×512 및 256×256 벤치마크에서 이전 모델들을 능가하는 성능을 보였으며, 256×256 벤치마크에서는 2.27이라는 최고 수준의 FID를 달성하였다.
Diffusion x Transformers
지난해 이미지 생성 분야에서 확산 모델이 놀라운 결과를 달성했다. 이 모델들 대부분이 핵심 구조로 컨볼루셔널 U-Net을 사용한다. 이는 꽤 놀라운 일이다, 왜냐하면 지난 몇 년 간 딥러닝에서 큰 화제는 다양한 분야에서 트랜스포머의 지배력이었기 때문이다. U-Net이나 컨볼루션에 특별한 것이 있는지, 그것들이 확산 모델에서 왜 그렇게 잘 작동하는지 궁금하다.
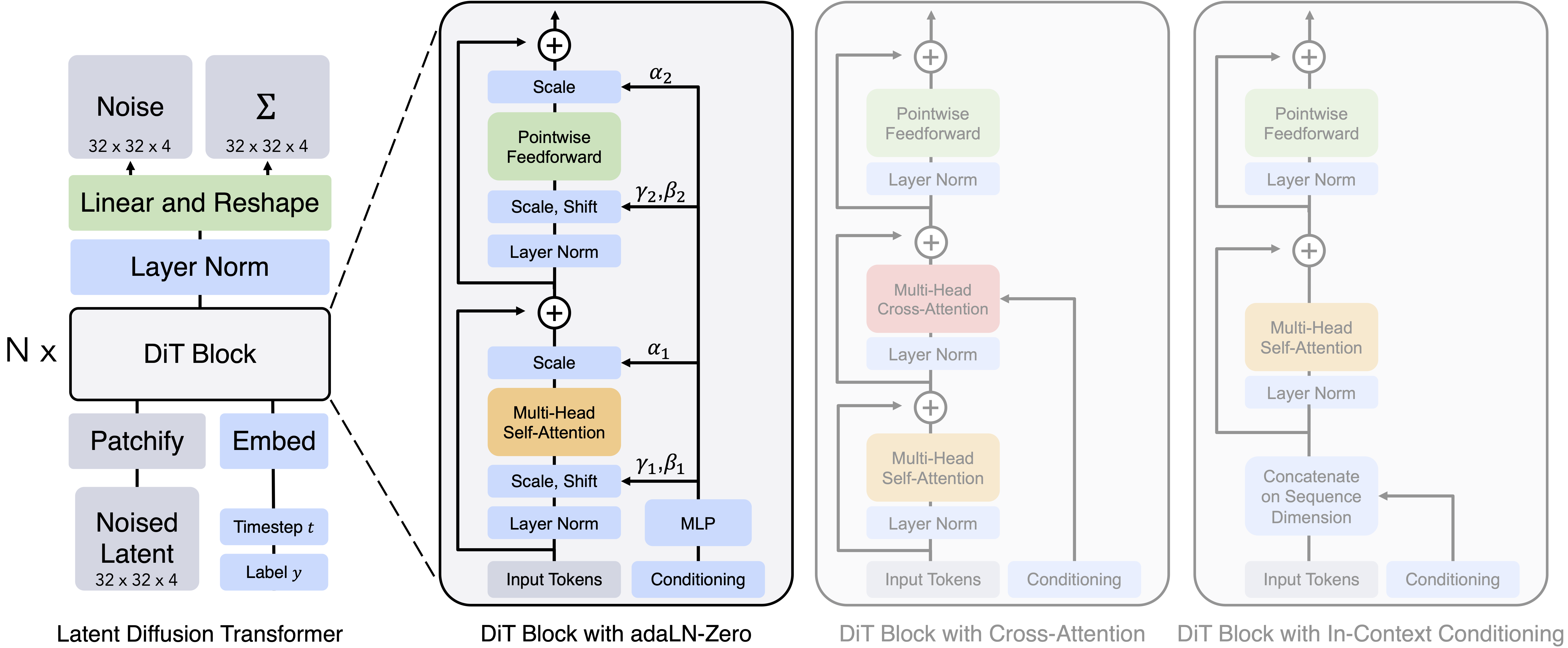
이 논문에서는 잠재 확산 모델(LDM)의 U-Net 백본을 트랜스포머로 대체했다. 이 모델들을 확산 트랜스포머, 줄여서 DiT라고 부른다. DiT 아키텍처는 표준 비전 트랜스포머(ViT)와 매우 유사하지만, 몇 가지 작지만 중요한 변형이 있다. 확산 모델은 diffusion timesteps이나 class labels과 같은 조건부 입력을 처리해야 한다. 이러한 입력을 주입하기 위한 다양한 블록 디자인을 실험했다. 가장 잘 작동하는 것은 adaptive layer norm layers(adaLN)를 갖춘 ViT 블록이다. 중요한 것은, 이 adaLN 레이어들이 블록 내의 residual connections 바로 앞에서 활성화를 조절하며, 각 ViT 블록이 identity function로 초기화된다는 점이다. 예를 들어 어떤 레이어나 블록이 identity function로 초기화되면 초기 학습 단계에서 입력 데이터에 아무런 변경을 가하지 않고 그대로 통과시킨다. 이러한 접근은 네트워크가 복잡한 함수를 학습하는 과정에서 안정성을 높이는 데 도움이 될 수 있다. 조건부 입력을 주입하는 방식을 단순히 바꾸는 것만으로도 FID 측면에서 엄청난 차이를 만든다. 이 변화는 좋은 성능을 얻기 위해 필요한 유일한 변화였다; 그 외에는 DiT가 꽤 표준적인 트랜스포머 모델이다.
Scaling DiT

트랜스포머는 다양한 분야에서 잘 확장된다는 것으로 알려져 있다. 확산 모델로서는 어떨까? 이 논문에서는 모델 크기와 입력 토큰 수라는 두 축을 따라 DiT를 확장한다.
Scaling model size. 모델의 깊이와 너비가 다른 네 가지 구성을 시도했다: DiT-S, DiT-B, DiT-L, 그리고 DiT-XL. 이 모델 구성들은 33M에서 675M의 매개변수와 0.4에서 119 Gflops의 범위를 가진다. 이들은 깊이와 너비를 함께 확장하는 것이 잘 작동한다는 ViT 문헌에서 차용한 것이다.
Scaling tokens. DiT에서 첫 번째 계층은 패치화(patchify) 계층이다. 패치화는 입력 이미지의 각 패치(또는 우리 경우에는 입력 잠재 변수)를 선형적으로 임베딩하여, 트랜스포머 토큰으로 변환한다. 작은 패치 크기는 많은 수의 트랜스포머 토큰에 해당한다. 예를 들어, 패치 크기를 반으로 줄이면 트랜스포머에 입력되는 토큰 수를 네 배 증가시키며, 이는 모델의 총 Gflops를 최소 네 배 증가시킨다. Gflops에 큰 영향을 미치지만, 패치 크기가 모델 매개변수 수에 의미 있는 영향을 미치지는 않는다는 점을 유의해야 한다. 즉, 그림에서 와 같이 주어진 패치 크기 $p \times p$ 에 대해, spatial representation (VAE에서나온 noise latent)인 $I \times I \times C$ 는 길이 $T=(I/p)^2$ 의 시퀀스로 “패치화(Patchify)” 되고, 은닉 차원(hidden dimension)은 $d$ 이다. 더 작은 패치 크기 $p$ 는 더 긴 시퀀스 길이를 결과로 하여, 따라서 더 많은 Gflops를 의미한다.
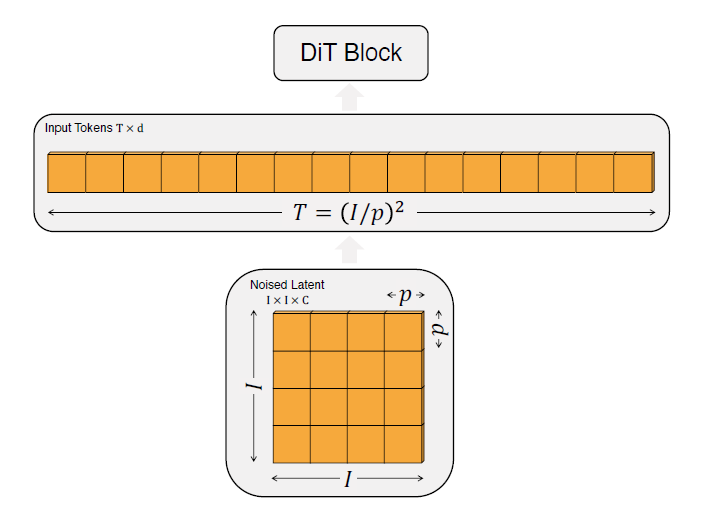
논문에서 네 가지 모델 구성 각각에 대해, 패치 크기가 8, 4, 그리고 2인 세 모델을 훈련시킨다(총 12개의 모델). 가장 높은 Gflops를 가진 모델은 가장 큰 XL 구성을 사용하고 패치 크기가 2인 DiT-XL/2이다.
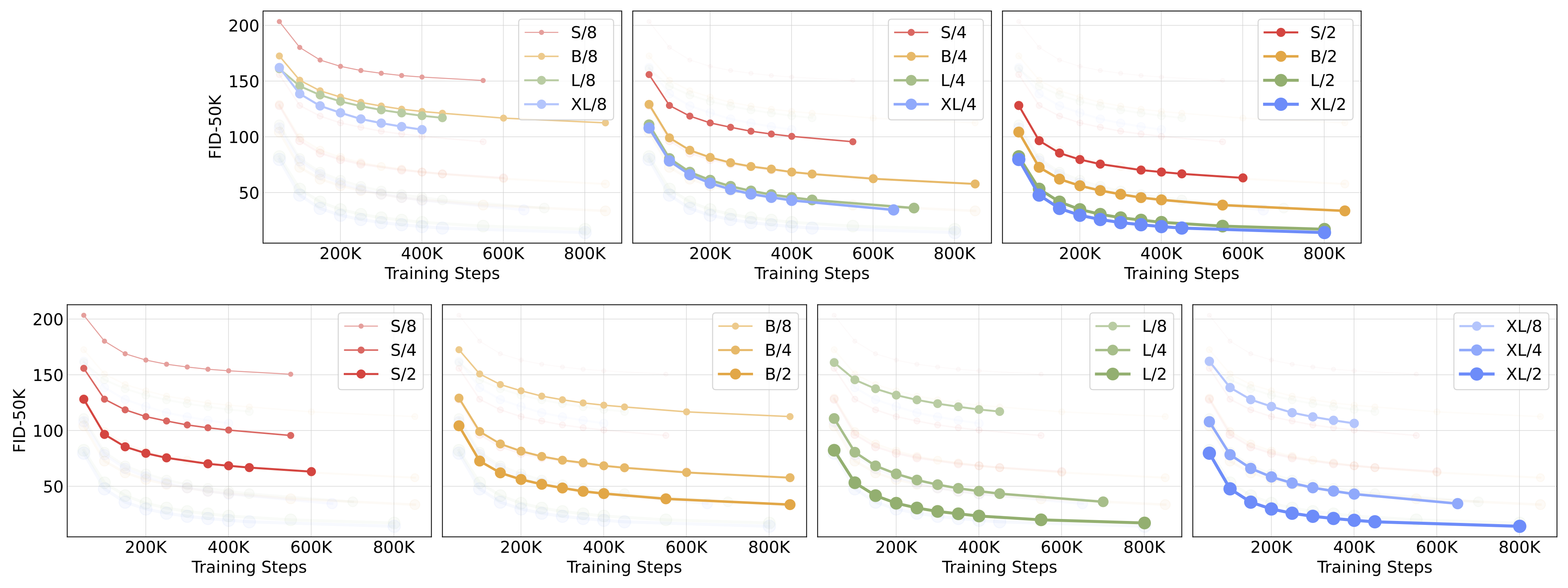
모델 크기와 입력 토큰 수를 확장하는 것은 프레셰 인셉션 거리(FID)로 측정한 DiT의 성능을 크게 향상시킨다. 다른 분야에서 관찰된 것처럼, 계산량—단순히 매개변수 수가 아닌—이 더 나은 모델을 얻는 데 있어 핵심으로 보인다. 예를 들어, DiT-XL/2는 뛰어난 FID 값을 얻지만, XL/8은 성능이 좋지 않다. XL/8은 XL/2보다 약간 많은 매개변수를 가지고 있지만 훨씬 적은 Gflops를 가진다. 또한 더 큰 DiT 모델들은 작은 모델들에 비해 계산 효율이 좋다는 것을 발견했다; 더 큰 모델들은 주어진 FID에 도달하기 위해 더 적은 훈련 계산량을 요구한다(자세한 내용은 논문을 참조).
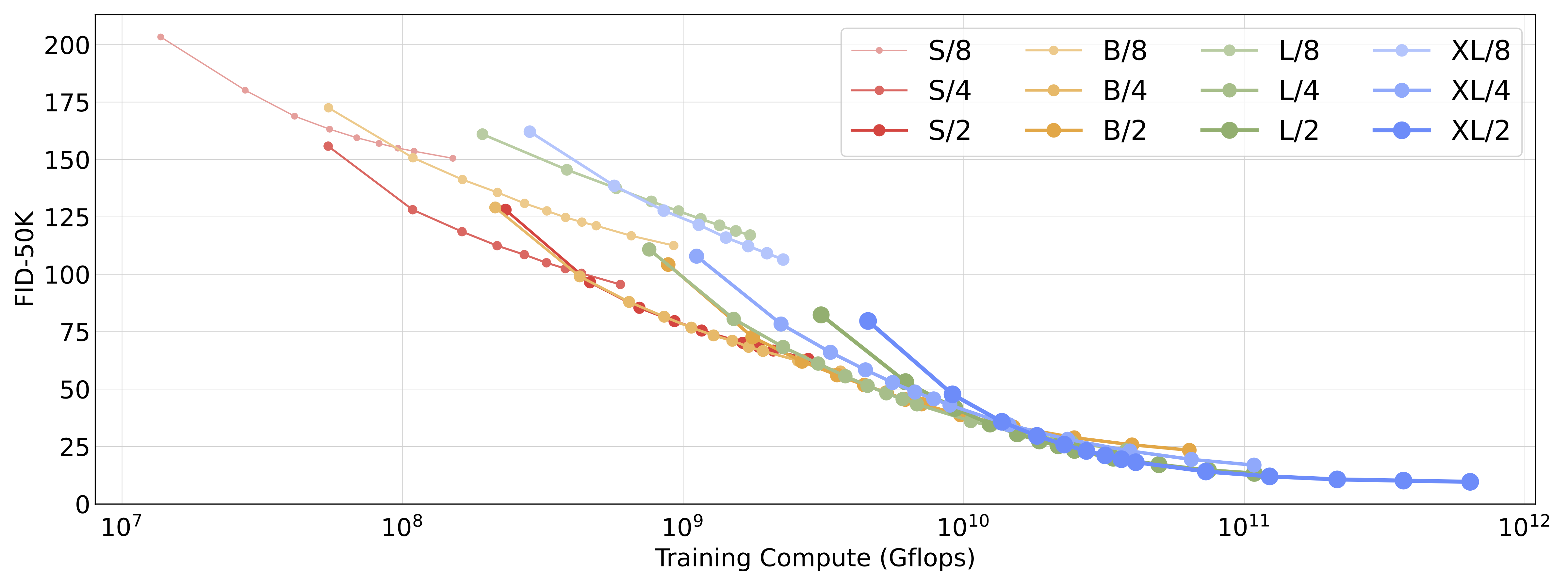
본 논문의 확장성 분석에 따르면, 충분한 시간 동안 훈련시킬 경우 DiT-XL/2가 분명 최고의 모델이다. 이 글의 나머지 부분에서는 XL/2에 집중할 것이다.
Comparison
256x256 및 512x512 해상도의 ImageNet에서 DiT-XL/2의 두 가지 버전을 각각 700만 스텝과 300만 스텝 동안 훈련시켰다. classifier-free guidance를 사용할 때, DiT-XL/2는 이전의 모든 확산 모델을 능가하여, 이전에 LDM(256x256)이 달성한 최고의 FID-50K 3.60을 2.27로 줄였다. XL/2는 다시 한 번 512x512 해상도에서 모든 이전 확산 모델을 능가하여, ADM-U가 달성한 이전 최고 FID 3.85를 3.04로 개선하였다.
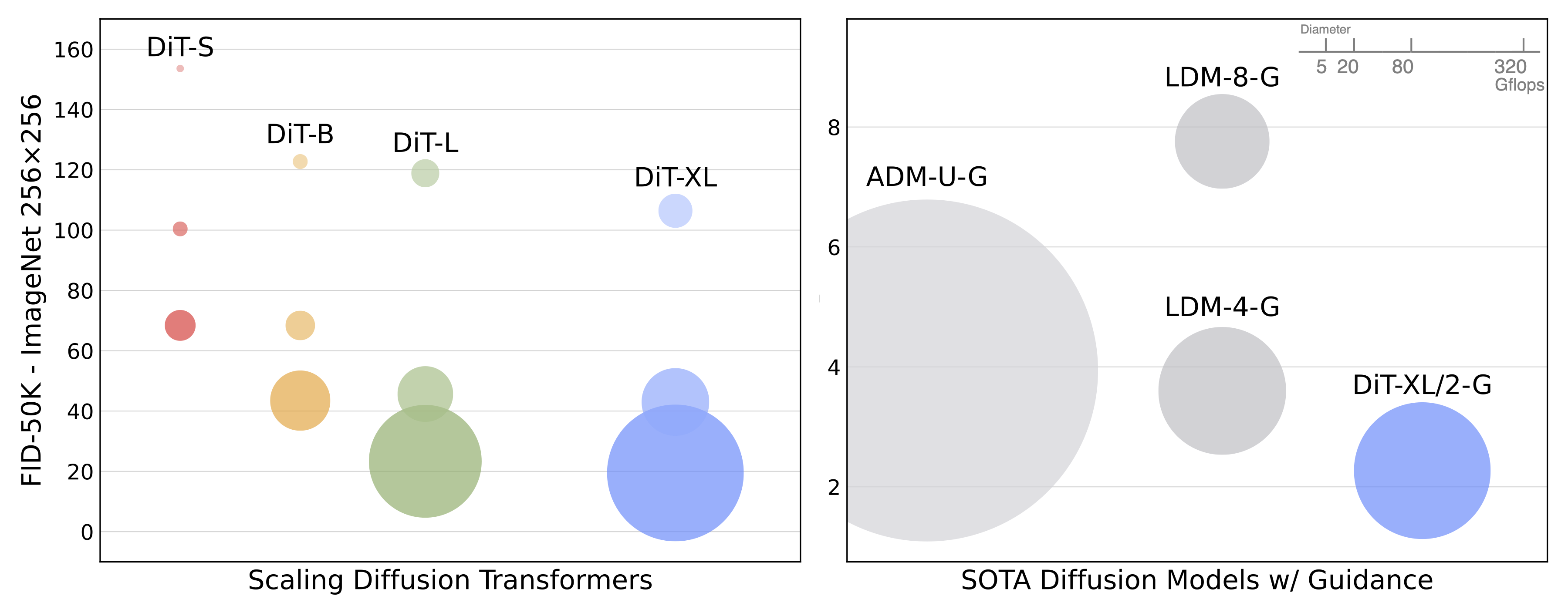
또한 좋은 FID 값을 얻을 뿐만 아니라, DiT 모델은 기준 모델들에 비해 계산 효율성 면에서도 우수하다. 예를 들어, 256x256 해상도에서 LDM-4 모델은 103 Gflops, ADM-U는 742 Gflops이며, DiT-XL/2는 119 Gflops이다. 512x512 해상도에서는 ADM-U가 2813 Gflops인 반면, XL/2는 단 525 Gflops이다.
Walking Through Latent Space
마지막으로, DiT-XL/2에 대한 몇 가지 잠재 공간 거닐기를 보여준다. 우리는 다양한 초기 노이즈 선택을 통해 부드럽게 이동하면서, 각 중간 이미지를 생성하기 위해 결정론적인 DDIM 샘플러를 사용한다.
DiT의 라벨 임베딩 공간을 통해서도 거닐 수 있다. 예를 들어, 여러 개의 개 품종과 “테니스 볼” 클래스의 임베딩 사이에서 선형적으로 보간할 수 있다.
위에 보이는 가장 왼쪽 열에서, DiT는 임베딩 사이를 단순히 보간함으로써 동물과 물체의 하이브리드를 생성할 수 있다 (similar to the dog-ball hybrid from BigGAN).
