DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

원문 링크: [Paper Link]
저자: Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
[Google Research, Boston Univerity]
[Dataset]
[BibTex]
번역자: Zhenghui Piao
Abstract
대규모 텍스트-이미지 모델은 AI의 진화에서 주목할 만한 도약을 이루어, 주어진 텍스트 프롬프트에서 고품질이고 다양한 이미지를 합성할 수 있게 되었습니다. 그러나 이러한 모델들은 주어진 참조 세트의 대상의 모습을 모방하고 다른 맥락에서 그들의 새로운 렌더링을 합성하는 능력이 부족합니다. 이 연구에서, 우리는 text-to-image diffusion model의 “개인화(personalization)”라는 새로운 접근 방법(사용자의 필요에 맞게 특수화하는 방법)을 제시합니다. 주어진 몇 개의 대상 이미지만으로 사전 훈련된 text-to-image model(Imagen, 그러나 우리의 방법은 특정 모델에 국한되지 않음)을 미세 조정하여, 그 특정 대상에 대한 고유 식별자를 모델과 연결하도록 학습합니다. 일단 대상이 모델의 출력 영역에 포함되면, 그 고유 식별자는 참조 이미지에 나타나지 않는 다양한 장면, 포즈, 뷰, 조명 조건에서 완전히 새로운 사실적인 이미지를 합성하는 데 사용될 수 있습니다. 모델이 이미 가지고 있는 기본적인 의미 해석 능력과 새롭게 개발된, 특정 클래스에 대한 중요 정보를 유지하는 방식을 사용하여, 우리의 기술은 대상의 주요 특징을 유지하면서 다양한 장면에서 대상을 합성할 수 있게 합니다. 우리는 이 기술을 여러 이전에 해결할 수 없었던 과제들에 적용했으며, 이에는 대상 재맥락화(recontextualization), 텍스트 가이드 뷰 합성(text-guided view synthesis), 외모 수정(appearance modification) 및 예술적 렌더링(artistic rendering)이 포함됩니다.
Background
특정 대상인 시계(shown in the real images on the left)와 같은 것을 다른 맥락에서 생성하는 것은 최신 텍스트-이미지 모델로는 매우 어려운 과제이며, 이때 시계의 핵심 시각적 특징을 고도로 유지하는 것은 더욱 도전적입니다. 시계의 모습을 자세히 설명하는 텍스트 프롬프트(“retro style yellow alarm clock with a white clock face and a yellow number three on the right part of the clock face in the jungle“)를 수십 번 반복해도 Imagen 모델 [Saharia et al., 2022]은 시계의 주요 시각적 특징을 재현하는 데 실패합니다(세 번째 열). 또한, 텍스트 임베딩이 공유된 언어-비전 공간에 있는 모델들, 예를 들어 DALL-E2 [Ramesh et al., 2022]도 주어진 대상의 외모를 재현하거나 맥락을 수정하는 데는 성공하지 못합니다(두 번째 열). 반면에, 우리의 접근 방식(오른쪽)은 시계를 높은 충실도로 재현하고 새로운 맥락(“정글 속 [V] 시계”)에서 시계를 합성할 수 있습니다.

Approch
우리의 방법은 대상(예: a specific dog)의 몇 장의 사진(일반적으로 3-5장이면 충분하다고 우리의 실험에서 나타남)과 해당 클래스 이름(예: “dog”)을 입력으로 받아, 대상을 지칭하는 고유 식별자를 인코딩하는 세밀하게 조정된/‘개인화(personalized)된’ text-to-image model을 반환합니다. 그런 다음, 추론 시에 다른 문장에 이 고유 식별자를 삽입하여 다양한 맥락에서 대상을 합성할 수 있습니다.
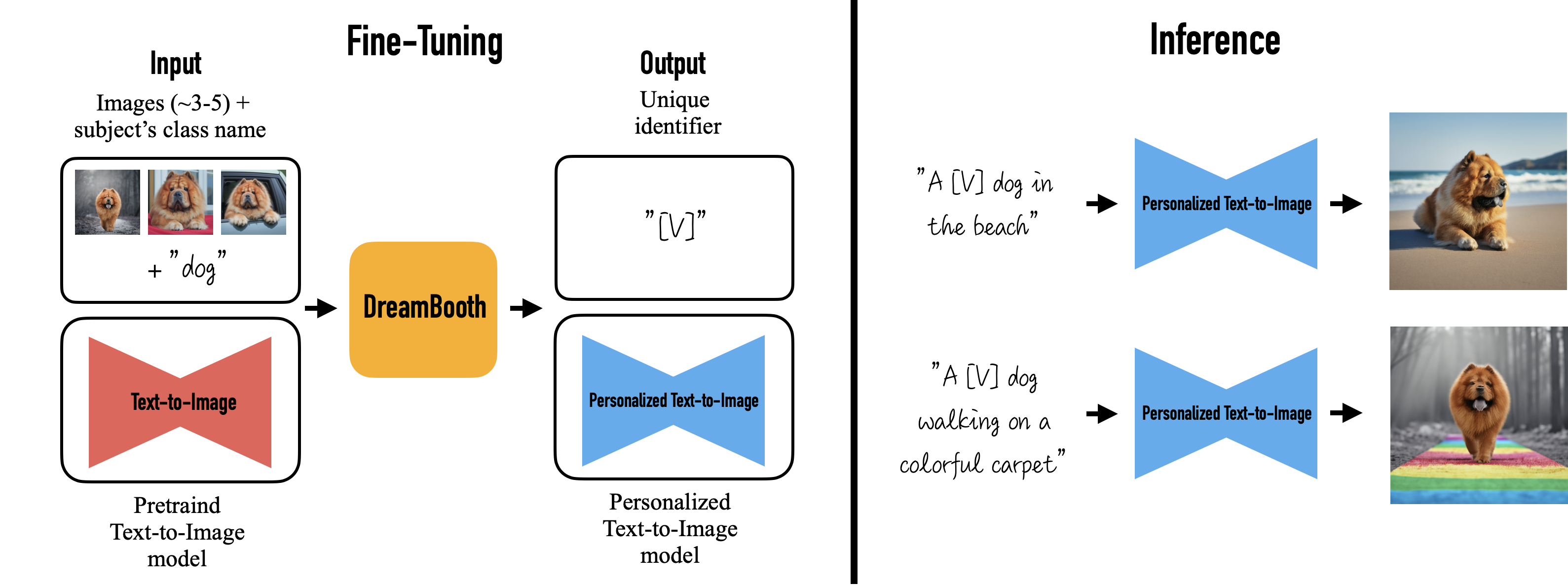
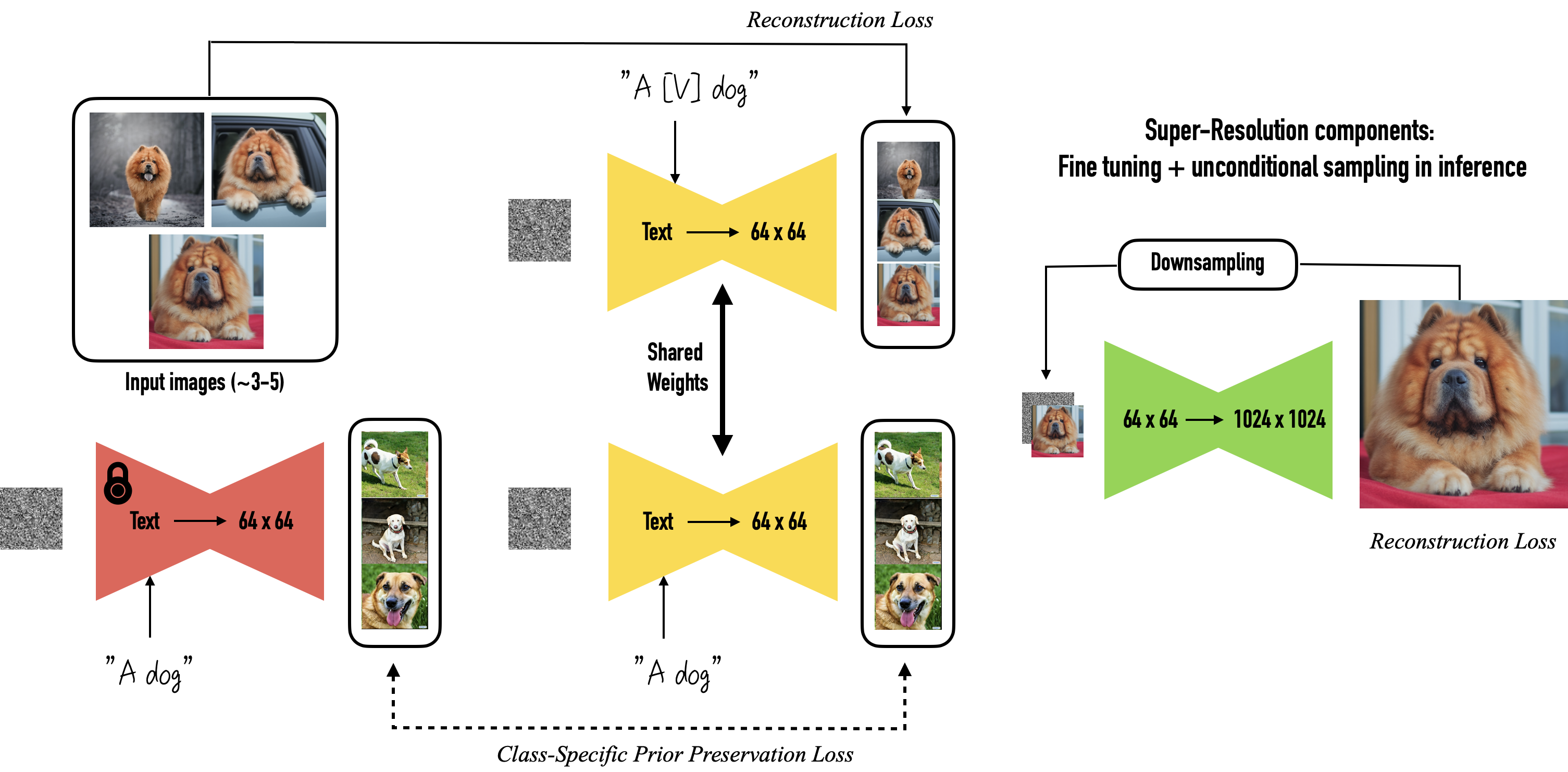
대상의 이미지 약 3-5장을 기반으로 text-to-image diffusion model을 두 단계로 미세 조정합니다: (a) 고유 식별자와 대상이 속한 클래스의 이름을 포함한 텍스트 프롬프트(예: “A photo of a [V] dog”)와 함께 입력 이미지를 이용해 저해상도 text-to-image model을 미세 조정하며, 동시에 클래스별 특정 보존 손실(preservation loss)을 적용합니다. “이 방법은 모델이 클래스에 대해 이미 알고 있는 의미적 정보를 활용하며, 텍스트 프롬프트에 클래스 이름을 추가함으로써 해당 클래스에 속하는 다양한 예시들을 만들어내는 데 도움을 줍니다(예: “A photo of a dog”). (b) 입력 이미지 세트에서 얻은 저해상도 및 고해상도 이미지 쌍을 이용하여 초고해상도 구성요소를 미세 조정합니다. 이를 통해 대상의 작은 세부사항에 대한 고도의 충실도를 유지할 수 있습니다.
Results
가방과 화병의 대상 인스턴스를 재배치하기 위한 결과. 우리의 방법을 사용하여 모델을 미세 조정함으로써, 우리는 다양한 환경에서 대상 인스턴스의 다양한 이미지를 높은 대상 세부 사항의 보존과 장면과 대상 간의 현실적인 상호 작용을 통해 생성할 수 있습니다. 각 이미지 아래에 조건부 프롬프트를 표시합니다.
Art Rendtion
유명한 화가들의 스타일로 제작된 우리 강아지 주제의 독창적인 예술 작품입니다. 훈련 세트에서 볼 수 없었던 많은 자세가 생성되었음을 지적합니다, 예를 들어 Van Gogh 묘사가 그러합니다. 또한 일부 묘사는 새로운 구성을 보여주고 화가의 스타일을 충실하게 모방하는 것처럼 보이며 - 이전 지식을 바탕으로 한 어떤 창의성을 암시합니다.

Text-Guided View Synthesis
저희 기술은 특정 고양이의 지정된 관점(왼쪽에서 오른쪽으로: 위, 아래, 옆면 및 뒷모습)에 대한 이미지를 합성할 수 있습니다. 생성된 포즈가 입력 포즈와 다르며, 포즈 변경에 따라 배경이 현실적으로 변하는 것을 주목할 수 있습니다. 또한 고양이 이마에 있는 복잡한 모피 무늬의 보존을 강조합니다.

Property Modification
첫 번째 줄에는 “a [color] [V] car” 프롬프트를 사용하여 색상 변경을 보여주고, 두 번째 줄에는 “a cross of a [V] dog and a [target species]” 프롬프트를 사용하여 특정 강아지와 다른 동물들과의 교차를 보여줍니다. 우리의 방법이 주어진 속성 변경을 수행하는 동안 대상의 정체성이나 본질을 나타내는 독특한 시각적 특징을 보존한다는 점을 강조합니다.

Accessorization
“경찰/셰프/마녀 복장을 한 [V] 강아지” 유형의 프롬프트가 주어지면 강아지에게 다양한 복장이나 액세서리를 입힐 수 있습니다. 대상 강아지와 복장이나 액세서리 사이에 현실적인 상호작용이 관찰되며, 가능한 옵션의 다양성이 큽니다.

수정해야 할 부분이나 의문이 있으신 분들은 메일로 연락 주시길 바랍니다.