High-Resolution Image Synthesis with Latent Diffusion Models (II)
기초부터 이해하는 Stable Diffusion (II): 어떻게 훈련하는가
몇 달 전, AIGC가 대유행을 일으키면서 고화질의 생성 이미지가 계속해서 등장했고, 그 중에서도 가장 중요한 오픈소스 모델인 Stable Diffusion이 기술적, 상업적으로 큰 인기를 끌었습니다. 이 모델은 빠른 속도로 지속적으로 발전하고 있습니다. 이전에 관련 지식이 없었던 초보자로서, 관련 기술 지식을 이해하기 위해 많은 글을 찾아보았고, 마침내 Jay Alammar의 글이 가장 이해하기 쉽다는 것을 발견하였습니다. 그래서 이 글을 간단히 번역하기로 결정했습니다. 이를 통해 더 많은 사람들이 이 강력한 기술을 처음부터 이해할 수 있게 돕고자 합니다.
원문이 길기 때문에, 여기서는 세 편의 글로 나누어 설명하겠습니다:
- 첫 번째 편, ‘무엇인가‘에 대해 주로 다룹니다. 여기에는 Stable Diffusion이 무엇인지, 그 안의 각 모듈이 무엇인지가 포함됩니다.
- 두 번째 편, 이 글에서는 ‘어떻게 하는가‘에 대해 다룹니다. 즉, Diffusion이 어떻게 훈련되고 사용되는지에 대한 문제입니다.
- 세 번째 편, ‘어떻게 제어하는가‘에 대해 다룹니다. 구체적으로, 의미 정보가 생성 이미지 과정에 어떻게 영향을 미치는지에 대해 설명합니다.
이제 본격적으로 두 번째 편의 소개에 들어가서, Diffusion을 어떻게 훈련하고 어떻게 사용하는지에 대해 이야기해보겠습니다.
원문 링크: The Illustrated Stable Diffusion
저자: Jay Alammar
번역자: Zhenghui Piao
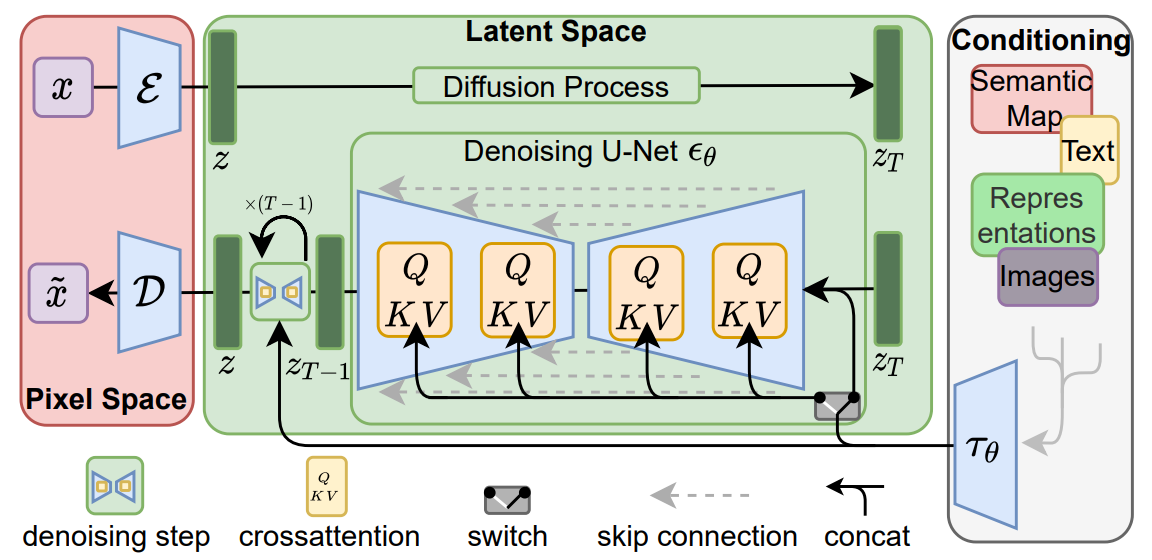
앞서 언급했듯이, Stable Diffusion에는 세 가지 주요 모듈이 있습니다. 이에는 텍스트 이해(Text Understander)로 의미 정보를 처리하는 모듈, 이미지 정보(Image Information Creator)로 이미지의 잠재 변수를 생성하는 모듈, 이미지 디코더(Image Decoder)로 잠재 변수를 사용하여 실제 이미지를 생성하는 모듈이 포함됩니다. 또한, 전체 이미지 생성 과정에 대해서도 더 깊이 이해하게 되었습니다. 우리는 벡터가 각 단계를 거치며 형태가 변화하는 것뿐만 아니라, 과정 중에 노이즈가 이미지로 변하는 전 과정을 시각화할 수 있었습니다. 따라서, Stable Diffusion의 작업 흐름을 대략적으로 이해한 후에, 이제 이 모델을 훈련하는 방법을 배워야 합니다.
1. Diffusion을 어떻게 훈련하는가
Diffusion 모델이 고품질 이미지를 생성할 수 있는 핵심 이유는 우리가 현재 매우 강력한 컴퓨터 비전 모델을 가지고 있기 때문입니다. 데이터셋이 충분히 크면, 우리의 강력한 모델은 어떤 복잡한 작업도 학습할 수 있습니다. 그렇다면 구체적으로 diffusion 내에서 UNet이 어떤 작업을 학습했을까요? 간단히 말해서, 바로 ‘노이즈 제거(De-noising)‘입니다.
그렇다면 노이즈 제거 작업을 위한 데이터셋은 어떻게 디자인할까요? 매우 간단합니다. 우리는 일반 사진에 노이즈를 추가하기만 하면 노이즈가 추가된 이미지를 얻을 수 있습니다. 예를 들어, 우리가 지금 금자탑의 사진을 가지고 있다고 가정해봅시다. 우리는 random 함수를 사용하여 강도가 강한 것부터 약한 것까지 다양한 강도의 노이즈를 생성합니다, 예를 들면 아래 그림에서 0~3까지 총 4가지 강도의 노이즈를 만듭니다. 이제 우리는 특정 강도의 노이즈를 선택합니다, 예를 들어 아래 그림에서 노이즈 1을 선택하고, 이 노이즈를 사진에 추가합니다:

이제 우리는 훈련 데이터셋 안의 한 장의 사진을 만들었습니다. 이와 같은 방식으로 사진을 선택하고, 다른 강도의 노이즈를 섞어서, 우리는 더 많은 훈련 데이터셋을 만들 수 있습니다. 예를 들어, 아래는 도서관의 사진을 선택하고 강도 2의 노이즈를 섞어서 조금 더 흐릿한 훈련 샘플을 만든 예입니다:

위 예시는 매우 간단한 것으로, 노이즈를 단지 네 가지 수준으로만 설정했습니다. 실제로는 노이즈의 등급을 더 세밀하게 나눌 수 있으며, 수십 또는 수백 가지 등급으로 분류하여 수천 개의 훈련 데이터셋을 생성할 수 있습니다. 예를 들어, 이제 우리가 노이즈를 100개 등급으로 설정한다면, 아래는 다양한 등급과 다양한 이미지를 조합하여 6개의 훈련 데이터셋을 만드는 과정을 보여줍니다:

이렇게 되면, 한 훈련 데이터셋 세트는 세 가지 요소를 포함합니다: 노이즈 강도(위 사진의 숫자), 노이즈가 추가된 사진(위 사진의 왼쪽 열의 이미지), 그리고 노이즈 이미지(위 사진의 오른쪽 열의 이미지)입니다. 훈련할 때 우리의 UNet은 알려진 노이즈 강도를 조건으로 하여, 노이즈가 추가된 사진에서 노이즈 이미지를 어떻게 계산하는지를 학습하면 됩니다. 주의할 점은, 우리는 노이즈가 없는 원본 이미지를 직접 출력하는 것이 아니라 UNet이 원본 이미지에 추가된 노이즈를 예측하게 하는 것입니다. 이미지를 생성할 때는 노이즈가 추가된 이미지에서 노이즈를 빼면 원본 이미지를 복원할 수 있습니다.
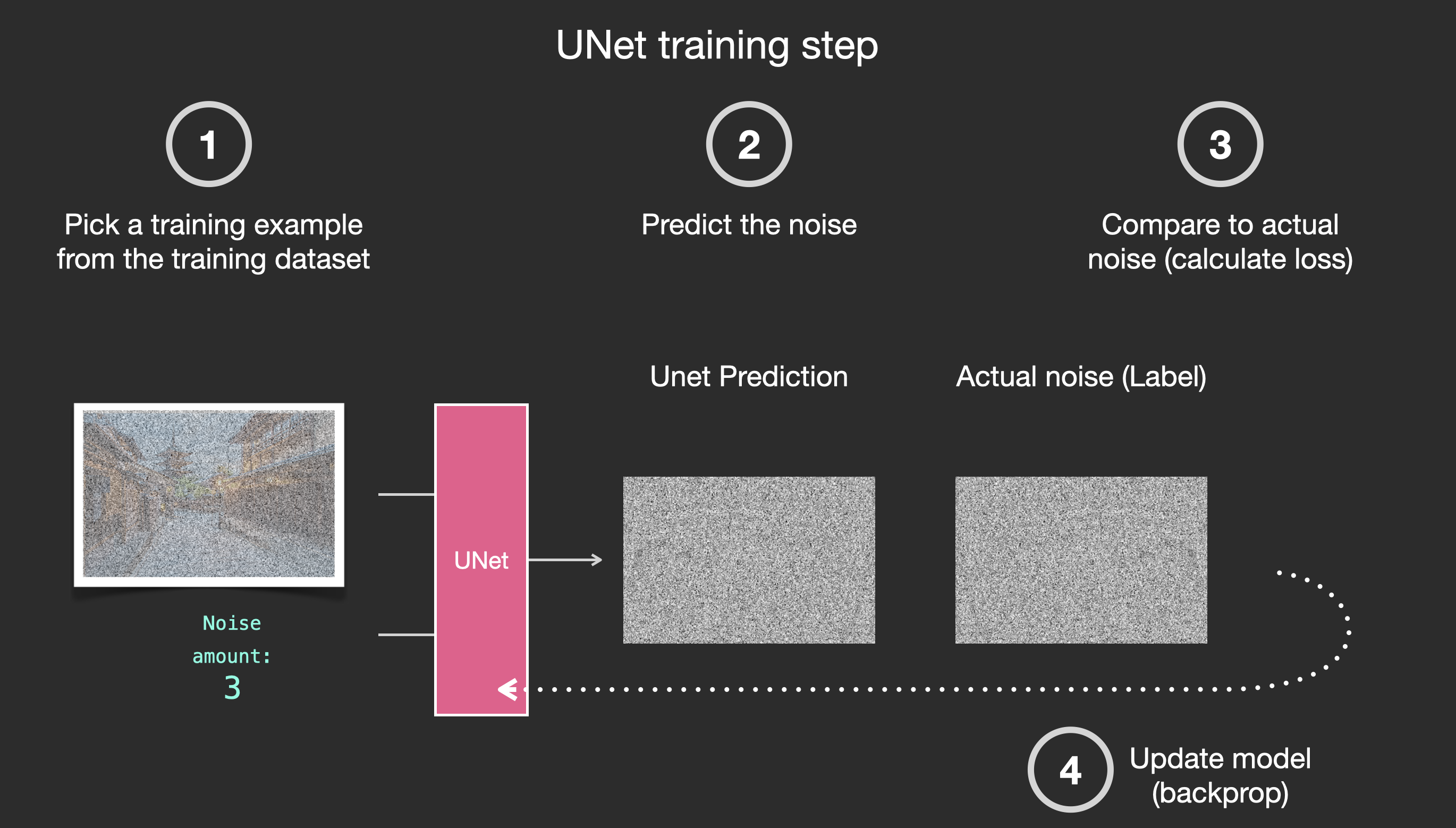
구체적인 훈련 과정은 아래 그림과 같이 총 네 단계로 진행됩니다:
- 훈련 데이터셋에서 노이즈가 추가된 한 장의 사진과 노이즈 강도를 선택합니다. 예를 들어, 아래에 있는 노이즈가 추가된 거리 사진과 노이즈 강도 3을 선택합니다.
- UNet에 입력하여 UNet이 노이즈 이미지를 예측하게 합니다. 예를 들어, 아래 그림의 UNet 예측과 같습니다.
- 실제 노이즈 이미지와의 차이를 계산합니다.
- 역전파를 통해 UNet의 파라미터를 업데이트합니다.
그렇다면 훈련을 마친 후, 우리는 어떻게 이미지를 생성할까요?
2. Diffusion이 어떻게 이미지를 생성하는가
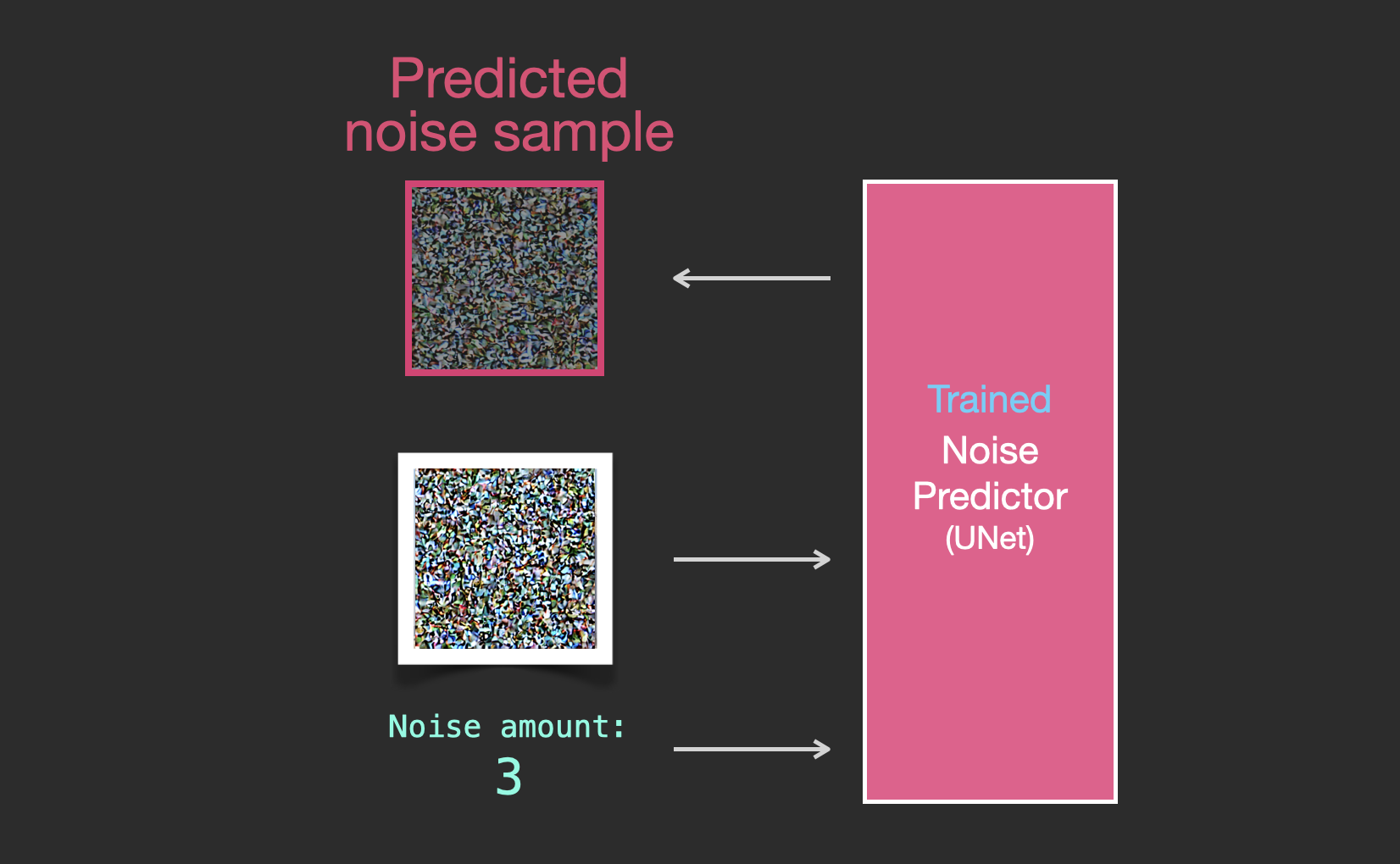
우리가 이미 위 단계에 따라 UNet을 성공적으로 훈련시켰다고 가정해봅시다. 이는 UNet이 노이즈가 추가된 이미지에서 노이즈를 추론할 수 있다는 것을 의미합니다. 아래 그림처럼, 노이즈 강도를 알고 있는 상황에서, UNet에 노이즈가 있는 이미지를 입력하면 UNet은 해당 이미지에 추가된 노이즈를 출력합니다:
이제 노이즈 이미지가 추론될 수 있으므로, 노이즈가 추가된 이미지에서 이 노이즈 이미지를 빼면, 쉽게 약간 노이즈가 제거된 이미지를 얻을 수 있습니다.
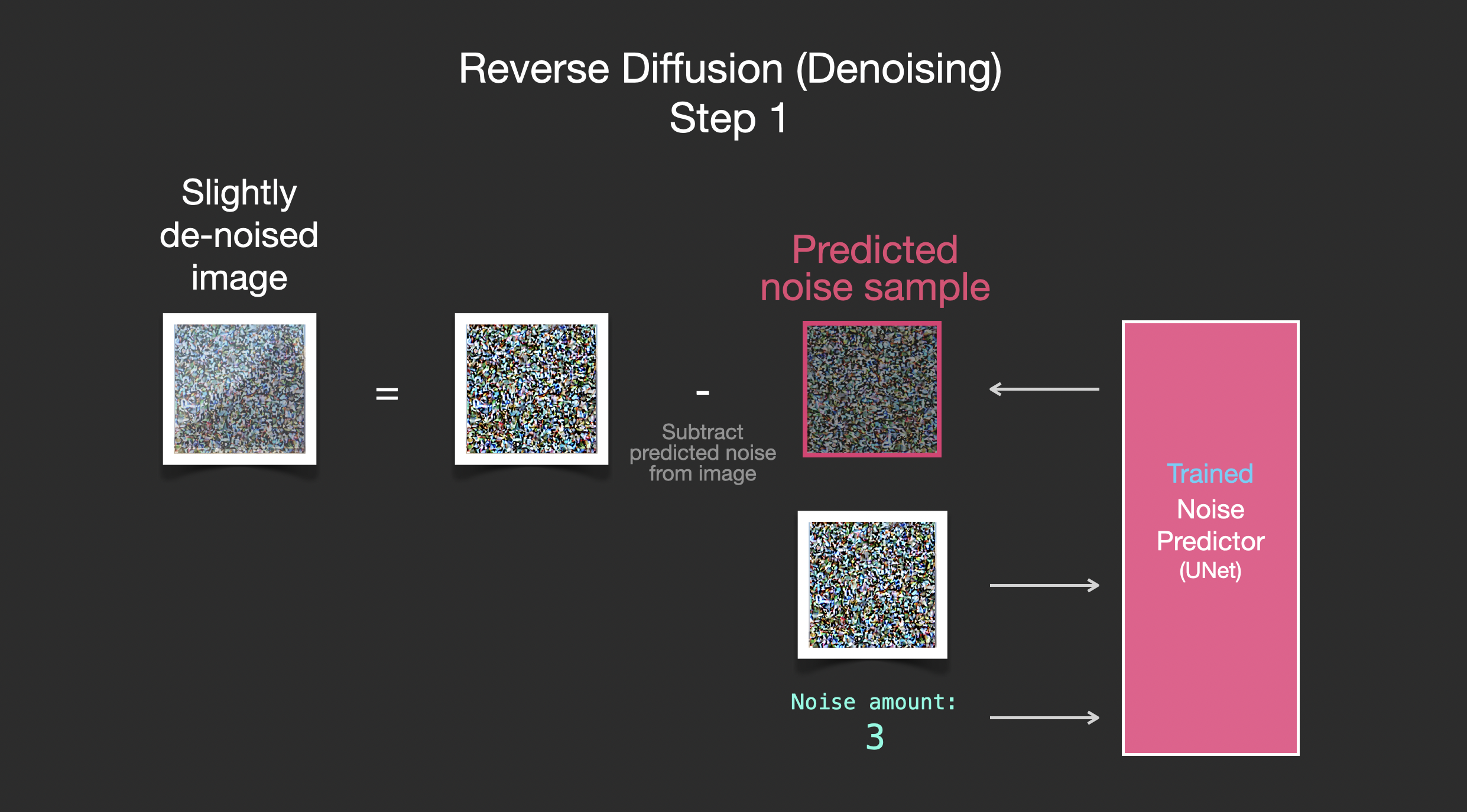
이 과정을 반복하여 노이즈 이미지를 예측하고, 다시 노이즈 이미지를 빼서 두 번째 단계의 노이즈 제거를 수행합니다:
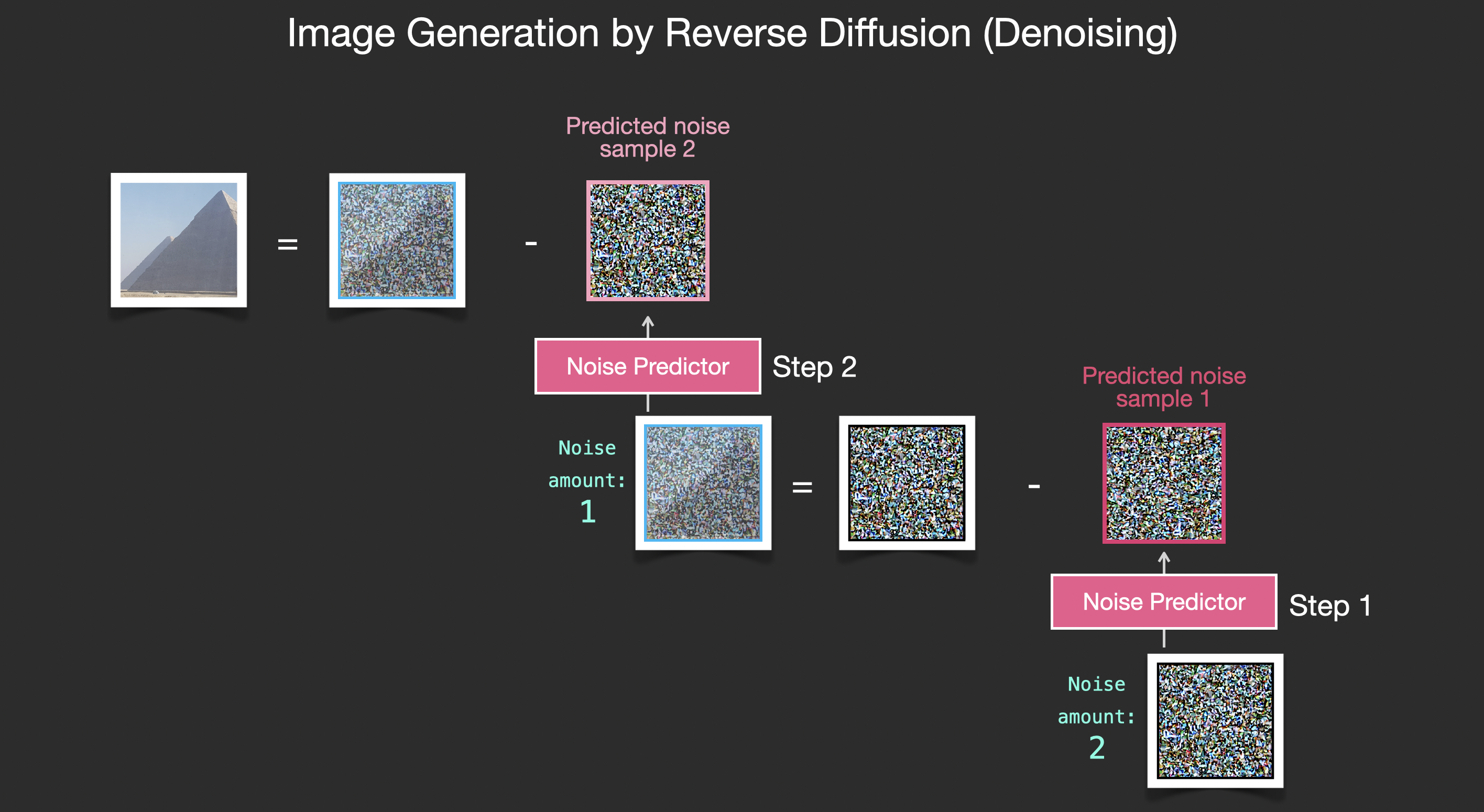
이 과정을 지속적으로 반복하여 노이즈가 있는 이미지에서 노이즈를 제거함으로써, 결국 우리는 훌륭한 이미지를 얻을 수 있습니다. 이 이미지는 훈련 데이터셋 분포에 가까우며, 훈련 데이터셋과 동일한 픽셀 패턴을 유지합니다. 예를 들어, 어떤 예술가의 데이터셋으로 훈련하면 미학적인 색상 분포를 따르게 되고, 실제 세계의 데이터셋으로 훈련하면 그 결과가 실제 세계의 규칙을 최대한 따르게 됩니다. 이제 당신은 Diffusion 모델의 기본 원리를 이해했으며, 이는 Stable Diffusion뿐만 아니라 OpenAI의 Dall-E 2와 Google의 Imagen에도 적용됩니다.
위의 과정에서 우리는 아직 텍스트와 의미 벡터의 제어를 도입하지 않았습니다. 즉, 위의 프로세스를 단순히 따른다면 멋진 이미지를 얻을 수는 있지만 최종 결과를 제어할 방법이 없습니다. 그렇다면 어떻게 텍스트 제어를 도입할까요? 이는 언어 모델과 Attention 메커니즘을 사용하여 의미를 도입하는 방법으로, 이 부분은 다음 글에서 설명하겠습니다.”
3. Conclusion
이전 글에서 Stable Diffusion의 각 모듈과 작업 흐름에 대해 소개한 후, 이번 글에서는 Diffusion이 어떻게 훈련되고 추론되는지에 대해 중점적으로 설명했습니다. 글의 마지막에서 이번 글의 내용을 간단히 요약해봅시다:
- Diffusion Training: ‘노이즈 강도, 노이즈 이미지, 노이즈가 추가된 이미지’를 훈련 데이터셋으로 사용하여 UNet을 훈련시켜, 노이즈가 추가된 이미지에서 추가된 노이즈를 추론하는 방법을 학습합니다.
- Diffusion inference: 훈련된 UNet을 사용하여 순수 노이즈로부터 단계별로 노이즈를 제거하여 합리적이고 정상적인 이미지를 얻습니다.
의미 정보가 이미지 생성 과정을 어떻게 제어하는지에 대해서는 다음 글에서 설명하겠습니다. 다음 글은 여기를 클릭하여 읽을 수 있습니다: 다음글
수정해야 할 부분이나 의문이 있으신 분들은 메일로 연락 주시길 바랍니다.