High-Resolution Image Synthesis with Latent Diffusion Models (III)
기초부터 이해하는 Stable Diffusion (III): 어떻게 제어하는가
몇 달 전, AIGC가 대유행을 일으키면서 고화질의 생성 이미지가 계속해서 등장했고, 그 중에서도 가장 중요한 오픈소스 모델인 Stable Diffusion이 기술적, 상업적으로 큰 인기를 끌었습니다. 이 모델은 빠른 속도로 지속적으로 발전하고 있습니다. 이전에 관련 지식이 없었던 초보자로서, 관련 기술 지식을 이해하기 위해 많은 글을 찾아보았고, 마침내 Jay Alammar의 글이 가장 이해하기 쉽다는 것을 발견하였습니다. 그래서 이 글을 간단히 번역하기로 결정했습니다. 이를 통해 더 많은 사람들이 이 강력한 기술을 처음부터 이해할 수 있게 돕고자 합니다.
원문이 길기 때문에, 여기서는 세 편의 글로 나누어 설명하겠습니다:
- 첫 번째 편, ‘무엇인가‘에 대해 주로 다룹니다. 여기에는 Stable Diffusion이 무엇인지, 그 안의 각 모듈이 무엇인지가 포함됩니다.
- 두 번째 편, ‘어떻게 하는가‘에 대해 다룹니다. 즉, Diffusion이 어떻게 훈련되고 사용되는지에 대한 문제입니다.
- 세 번째 편, 이 글에서는 ‘어떻게 제어하는가‘에 대해 다룹니다. 구체적으로, 의미 정보가 생성 이미지 과정에 어떻게 영향을 미치는지에 대해 설명합니다.
이제 본격적으로 세 번째 글의 소개에 들어가서, 의미 정보가 어떻게 이미지 생성 과정에 영향을 미치는지에 대해 이야기해 보겠습니다.
원문 링크: The Illustrated Stable Diffusion
저자: Jay Alammar
번역자: Zhenghui Piao
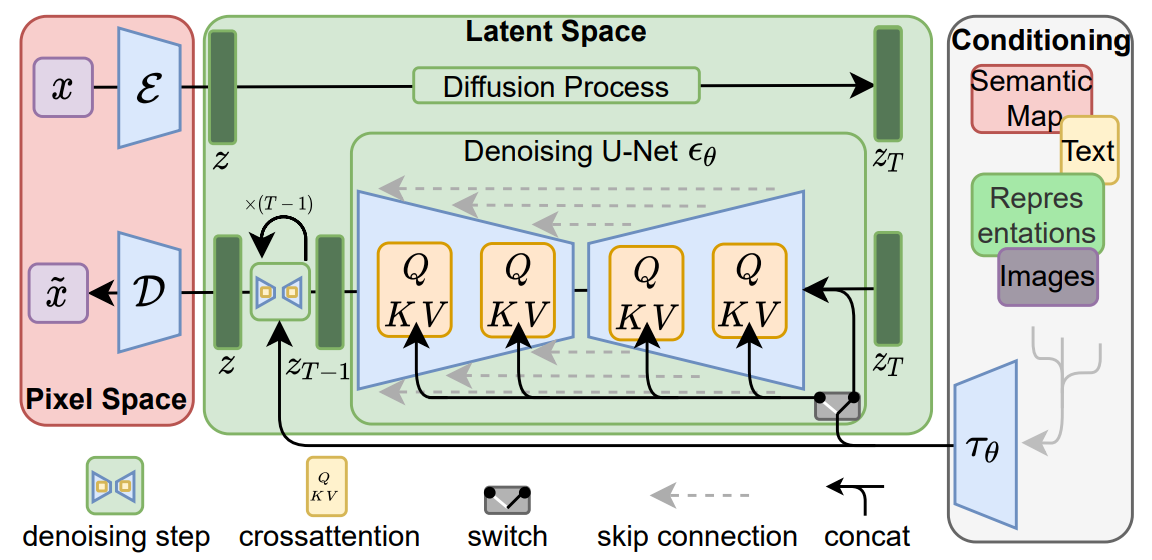
이전 글에서 우리는 Stable Diffusion의 UNet을 어떻게 훈련하는지, 그리고 훈련된 UNet을 어떻게 사용하여 노이즈를 제거하고 이미지를 생성하는지에 대해 집중적으로 설명했습니다. 하지만 아직 언급하지 않은 중요한 부분이 하나 있습니다. 그것은 바로 제어 가능성입니다. 우리는 어떻게 언어를 사용하여 최종 생성된 결과를 제어할 수 있을까요? 답은 간단합니다 —— 바로 Attention 메커니즘입니다. 첫 번째 글에서 언급했듯이, UNet은 노이즈 이미지뿐만 아니라 Text Encoder를 사용하여 미리 추출한 의미 정보도 받아야 합니다. 그렇다면 이 의미 정보는 이미지 생성 과정에서 어떻게 사용될까요? 우리는 Attention 메커니즘을 사용하여 UNet의 내부에서 계속해서 결합합니다. 아래 그림의 각 노란색 작은 사각형은 Attention 메커니즘 사용을 나타냅니다. Attention 메커니즘을 사용할 때마다 이미지 정보와 의미 정보의 결합이 발생합니다. UNet 내부에서는 이러한 작업이 많은 횟수에 걸쳐 반복되며, 마지막 UNet까지 이 결합 과정이 계속됩니다.
누군가는 의문을 제기할 수도 있습니다. 의미 정보가 의미 정보이고, 이미지 정보가 이미지 정보인데, 어떻게 Attention을 사용하여 이 둘을 결합할 수 있을까요? 컴퓨터는 어떻게 이 두 가지 전혀 다른 정보를 연결할 수 있을까요? 이것은 이 글의 주인공인 CLIP 모델에 대해 이야기해야 할 때입니다.
1. CLIP 모델 소개
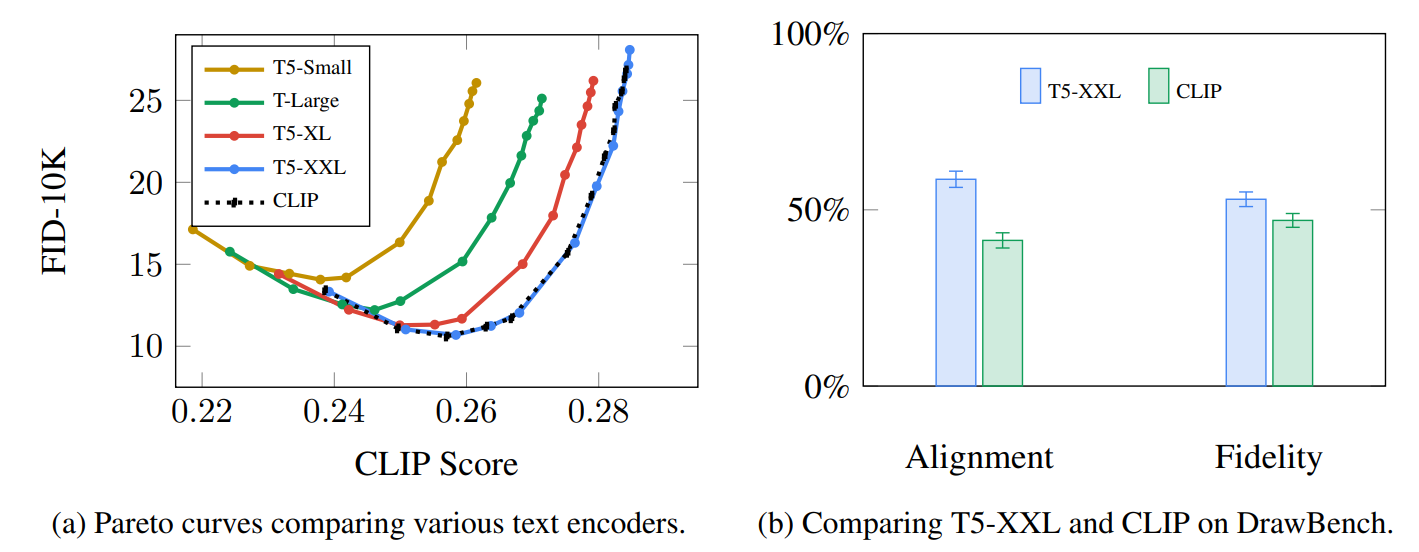
2018년 BERT가 출시된 이후, Transformer 기반 언어 모델이 주류가 되었습니다. Stable Diffusion의 초기 버전은 GPT 기반의 CLIP 모델을 사용했으며, 최근 2.x 버전에서는 더 새롭고 개선된 OpenCLIP으로 변경되었습니다. 언어 모델의 선택은 의미 정보의 우수성을 직접 결정하며, 의미 정보의 좋고 나쁨은 다시 이미지의 다양성과 제어 가능성에 영향을 미칩니다. Google은 Imagen 논문에서 다양한 언어 모델이 생성 결과에 미치는 영향에 대한 실험을 진행했으며, 다른 언어 모델들이 결과에 상당한 영향을 미치는 것을 발견할 수 있습니다.
그렇다면 CLIP과 같은 언어 모델은 어떻게 훈련되는 것일까요? 어떻게 인간 언어와 컴퓨터 비전을 결합하는 것일까요? 이제 이에 대해 자세히 알아보겠습니다.
먼저, 인간 언어와 컴퓨터 비전을 결합한 모델을 훈련시키려면, 인간 언어와 컴퓨터 비전을 결합한 데이터셋이 필요합니다. CLIP은 아래와 같은 데이터셋에서 훈련되었는데, 이미지 데이터는 무려 4억 장에 달합니다. 사실 이 데이터들은 모두 인터넷에서 크롤링하여 수집한 것이며, 수집된 데이터와 함께 그들의 태그나 주석도 함께 크롤링되었습니다.

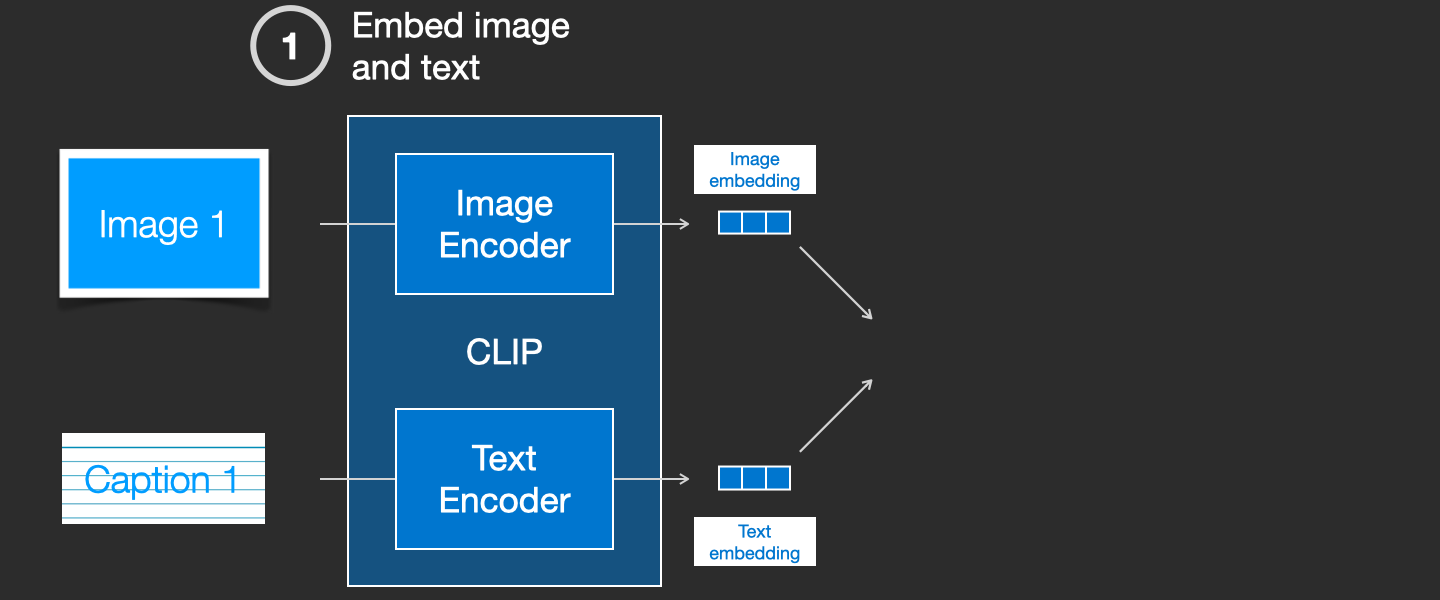
CLIP 모델은 이미지 인코더와 텍스트 인코더를 포함합니다. 훈련 과정은 다음과 같이 이해할 수 있습니다: 우리는 먼저 훈련 데이터셋에서 임의의 이미지와 텍스트를 선택합니다. 주목할 점은, 텍스트와 이미지가 반드시 일치할 필요는 없습니다. CLIP 모델의 임무는 이미지와 텍스트가 일치하는지 예측하는 것이며, 이를 통해 훈련을 진행합니다. 텍스트와 이미지를 임의로 선택한 후, 이미지 인코더와 텍스트 인코더를 사용하여 각각 두 개의 임베딩 벡터로 압축합니다. 이를 이미지 임베딩과 텍스트 임베딩이라고 합니다.
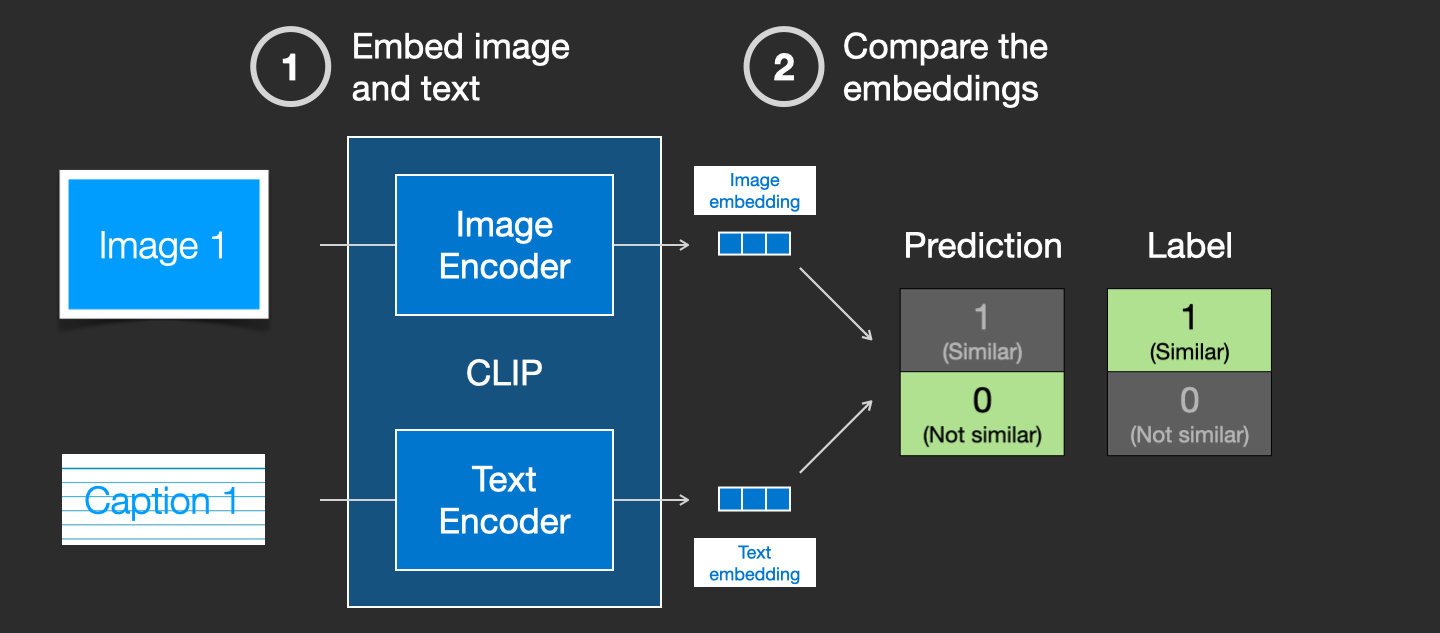
그 다음으로, 우리는 두 임베딩 벡터 간의 유사성을 코사인 유사도로 비교하여 임의로 선택한 텍스트와 이미지가 일치하는지 판단합니다. 처음에는 이미지와 텍스트가 잘 매칭되어 있더라도, 두 인코더가 막 초기화되었기 때문에 파라미터가 혼란스럽고, 따라서 두 임베딩 벡터도 혼란스러울 것이므로, 계산된 유사도는 종종 0에 가깝게 나타납니다. 이는 아래 그림과 같은 상황을 초래합니다. 이미지와 텍스트가 일치하는데도 불구하고, 레이블은 ‘similar’임에도 불구하고, 코사인 유사도로 계산된 예측은 ‘not similar’로 나타날 수 있습니다:
이때, 레이블(‘similar’)과 예측 결과(‘not similar’)가 일치하지 않으면, 이 결과에 따라 두 인코더의 파라미터를 역전파하여 업데이트합니다:
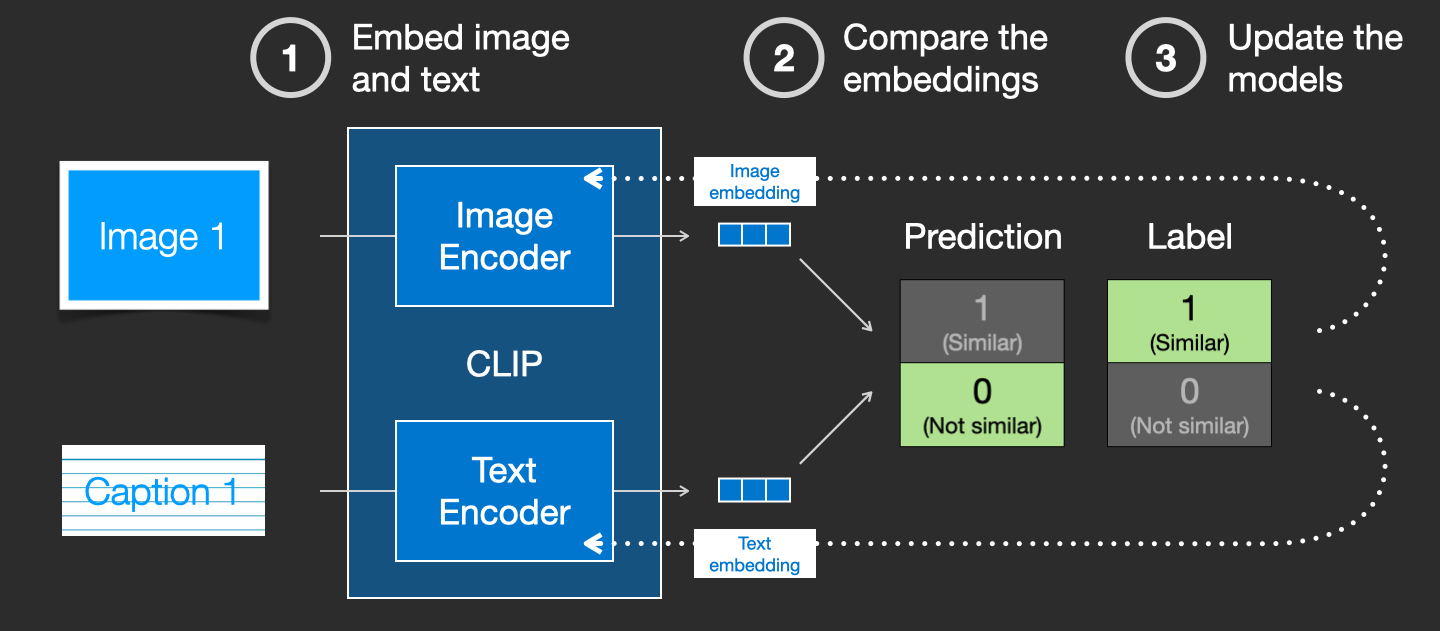
이러한 역전파 과정을 지속적으로 반복함으로써, 우리는 두 인코더를 효과적으로 훈련시킬 수 있습니다. 매칭되는 이미지와 텍스트에 대해, 이 두 인코더는 결국 유사한 임베딩 벡터를 출력하게 되고, 코사인 유사도 계산을 통해 1에 가까운 결과를 얻을 수 있습니다. 반면, 매칭되지 않는 이미지와 텍스트의 경우, 이 두 인코더는 매우 다른 임베딩 벡터를 출력하여 코사인 유사도가 0에 가까워집니다. 이 시점에서, CLIP에 작은 개의 사진과 “작은 개 사진”이라는 텍스트 설명을 제공하면, CLIP 모델은 두 개의 유사한 임베딩 벡터를 생성하여 텍스트와 이미지가 일치한다고 판단합니다. 이때, 컴퓨터 비전과 인간 언어라는 두 서로 관련 없는 정보가 CLIP을 통해 결합되어, 두 정보는 통합된 수학적 표현을 가지게 됩니다. 당신은 텍스트 인코더를 사용하여 텍스트를 이미지 정보로 변환할 수도 있고, 이미지 인코더를 사용하여 이미지를 언어 정보로 변환할 수도 있으며, 둘은 서로 상호 작용할 수 있습니다. 이것이 바로 Diffusion 모델이 텍스트를 통해 이미지를 생성할 수 있는 비밀입니다.
주목할 점은, CLIP을 훈련할 때는 word2vec을 훈련할 때처럼, 매칭되는 이미지와 텍스트만을 선택하는 것이 아니라, 기계가 인식할 수 있도록 완전히 매칭되지 않는 이미지와 텍스트도 적절히 선택하여, 긍정적인 샘플의 수를 균형있게 만들어주어야 한다는 것입니다.
2. 이미지에 의미 부여하기
훈련된 CLIP 모델을 통해, 우리는 의미 정보와 컴퓨터 비전 정보를 연결하는 완벽한 도구를 갖게 되었습니다. 그렇다면 CLIP 모델을 어떻게 사용할까요? 하나의 간단한 아이디어는, 특정 텍스트에 대해 CLIP의 텍스트 인코더를 사용하여 임베딩 벡터로 압축하는 것입니다. UNet의 노이즈 제거 과정 중에, 우리는 이 임베딩 벡터를 계속 Attention 메커니즘을 통해 노이즈 제거 과정에 주입함으로써 지속적으로 의미 정보를 추가할 수 있습니다.
지난 글에서, 우리는 의미 정보 없이 UNet의 입력과 출력 상황을 소개했습니다. 대략적으로 아래 그림과 같은 상황이었는데, 입력은 노이즈 강도와 노이즈가 추가된 이미지였고, 출력은 노이즈가 추가된 이미지에 추가된 노이즈였습니다.
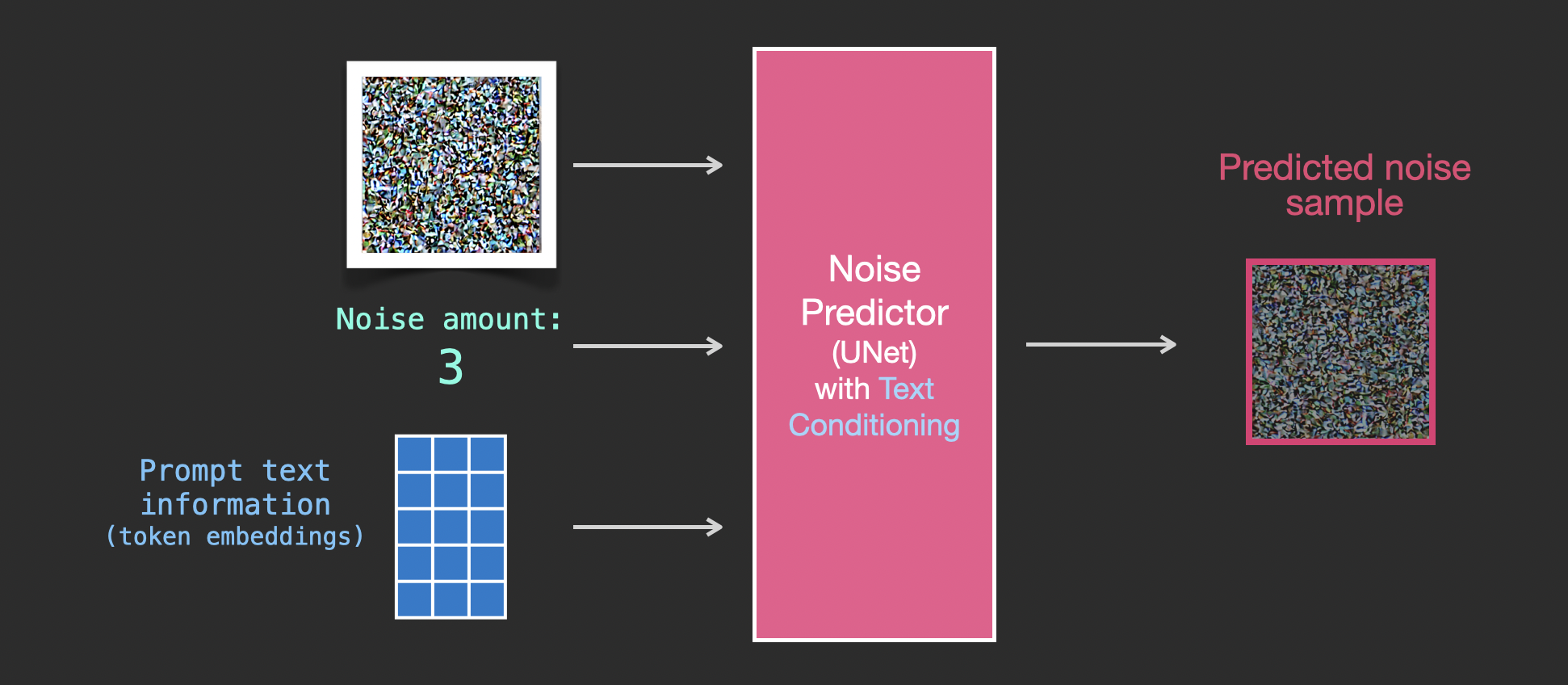
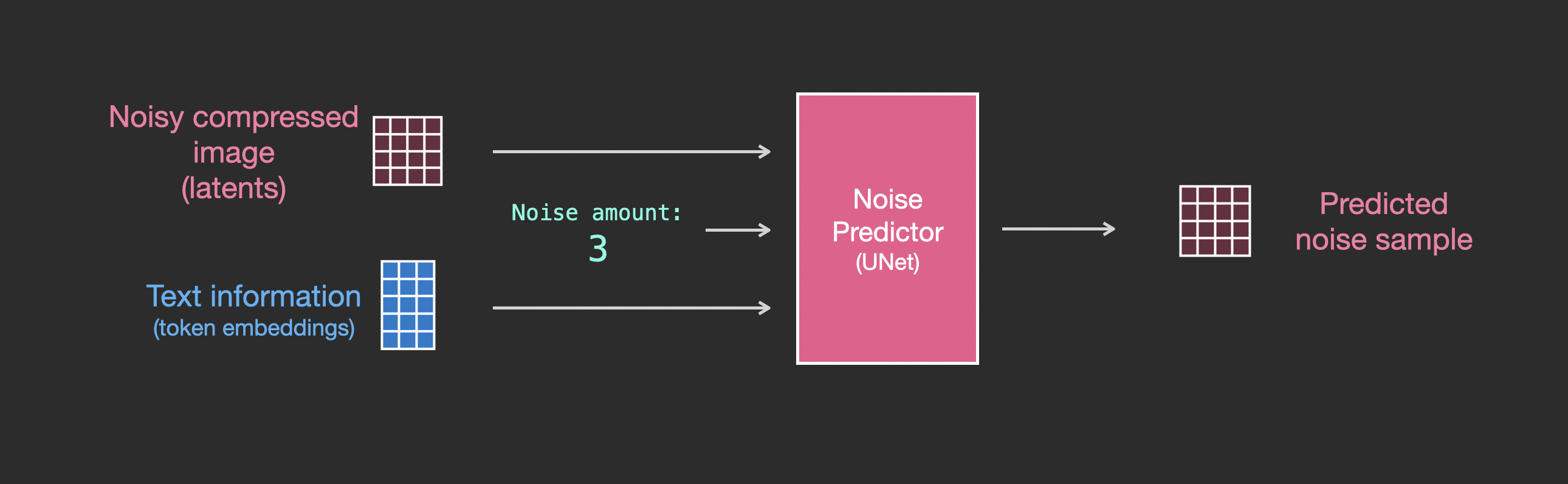
이제 의미 임베딩 벡터가 있으니, 약간의 수정을 거쳐 새로운 입력-출력 관계도를 가질 수 있습니다. 의미 임베딩 벡터는 아래 그림에서 파란색 3x5 사각형으로 나타납니다:
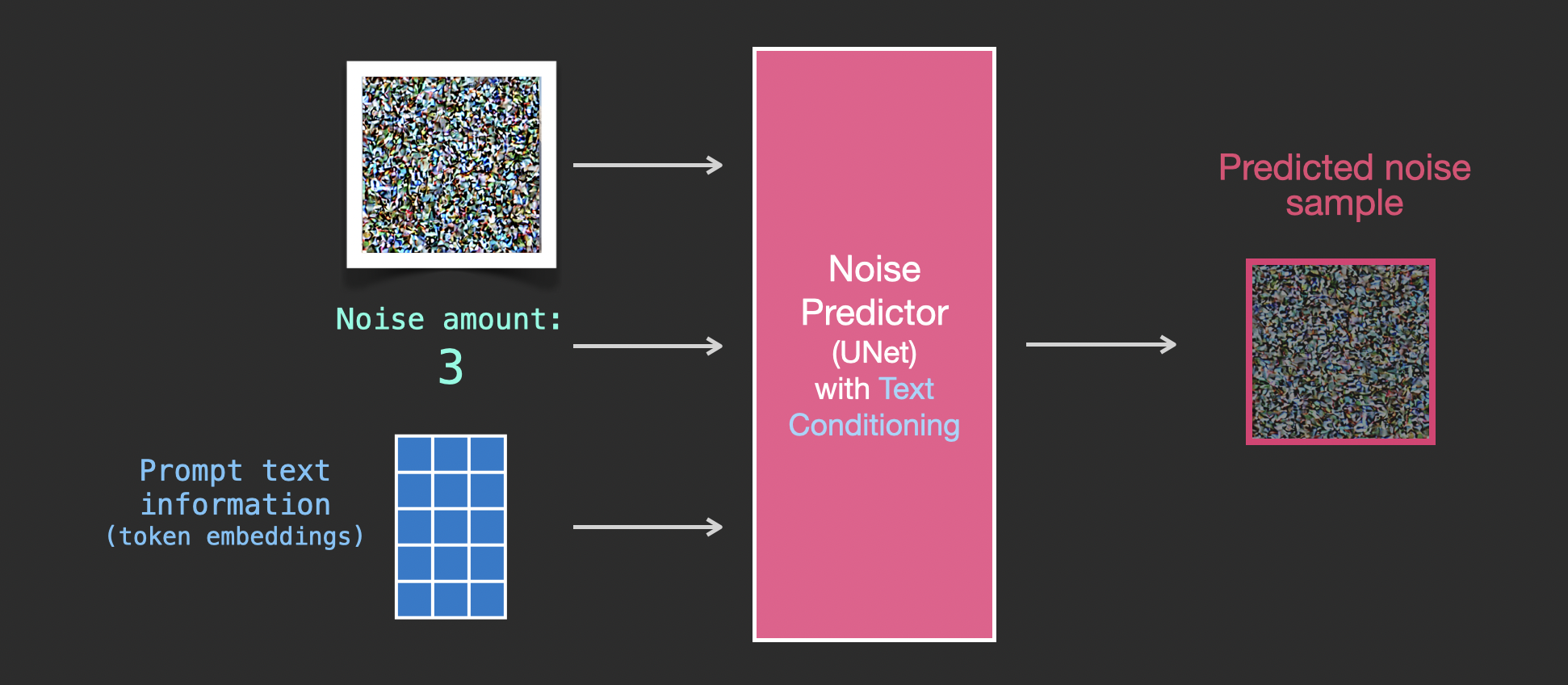
훈련 데이터셋에는 이제 텍스트 데이터 쌍이 추가되었으며, 이에 따라 입력이 노이즈 강도 + 노이즈가 추가된 이미지 + 텍스트로 변화했습니다:

이 과정에서 의미 벡터가 어떻게 작용하는지 더 명확하게 이해하기 위해서는, 우리는 UNet 내부에서 어떻게 작동하는지 더 깊이 파악해야 합니다.
3. 텍스트 조건이 없을 때의 UNet
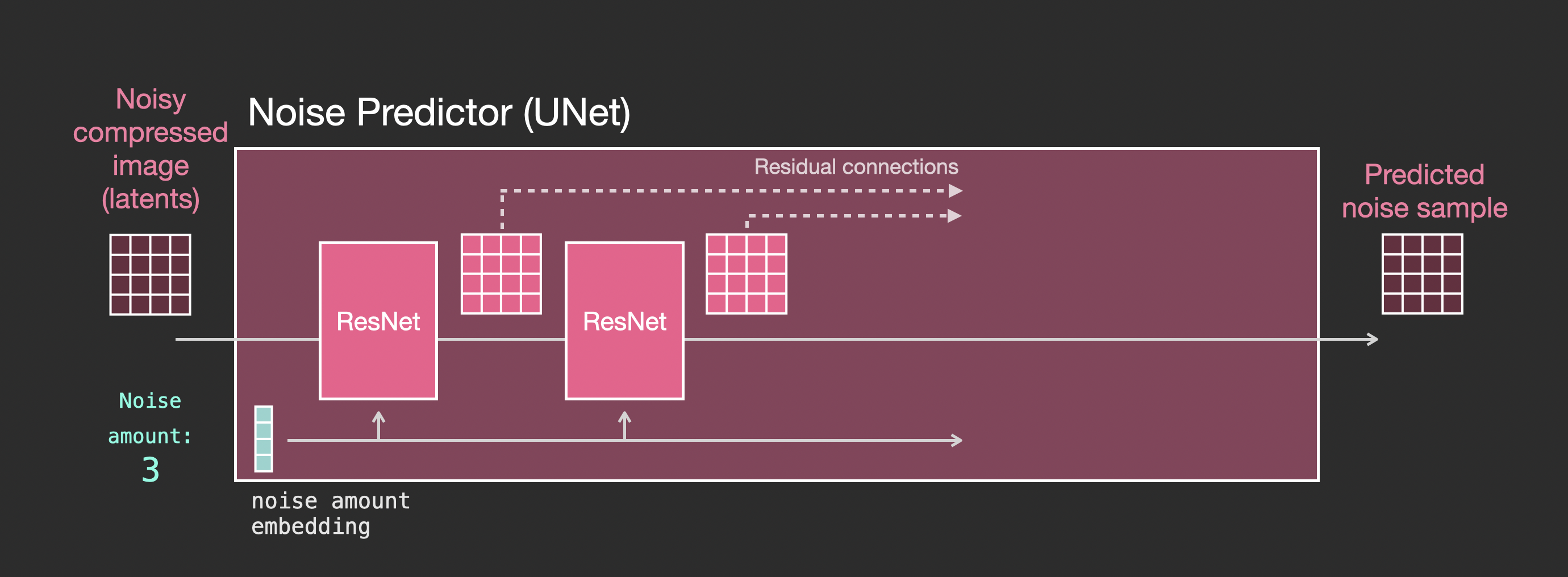
먼저, 텍스트가 없을 때 UNet의 거시적인 작업 모드는 이미 잘 알고 있습니다. UNet의 입력은 노이즈가 추가된 이미지와 노이즈 강도이며, 출력은 노이즈가 추가된 이미지 위에 추가된 노이즈입니다:
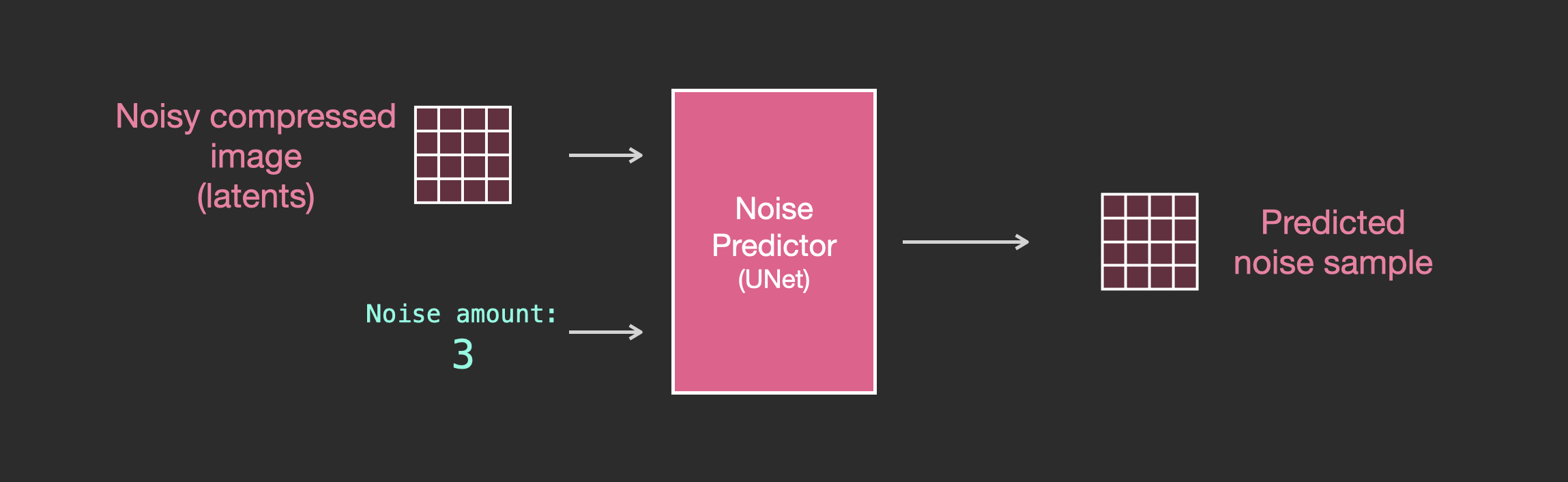
그런 다음, UNet 내부에서 무엇이 일어나는지 더 자세히 살펴보기 위해서, 위 그림에서 UNet을 나타내는 작은 분홍색 블록을 확대해 볼 수 있습니다. 아래 그림에 나타난 것처럼, 전체 UNet 내부의 프로세스는 다음과 같은 특징을 가지고 있습니다:
- 전체 UNet은 일련의 ResNet으로 구성되어 있습니다.
- 각 레이어의 입력은 이전 레이어의 출력입니다.
- 일부 출력은 잔여 연결을 통해 후속 레이어로 직접 건너뛰며, 아래 그림의 점선과 같습니다. 이러한 Residual + Skip 과 스킵 연결 조합은 UNet의 고전적인 아이디어입니다.
- 노이즈 강도는 임베딩 벡터로 변환되어 각각의 하위 ResNet 레이어에 입력됩니다. 이것이 노이즈 강도가 UNet의 핵심을 제어하는 근본 원리입니다.
4. 텍스트 조건이 있을 때의 UNet
텍스트 없이 UNet가 어떻게 작동하는지 이해한 후, 이제 텍스트 처리를 추가해야 합니다. 먼저, 거시적인 입력과 출력을 살펴보면, 위에 비해 token embedding이 추가된 것을 볼 수 있습니다.
우리는 이제 분홍색 UNet 모듈 내부에서 무슨 일이 일어나는지 더 자세히 살펴보겠습니다. 아래 그림에서 보이듯이, 각각의 ResNet은 이제 인접한 ResNet과 직접 연결되지 않고, 중간에 Attention 모듈이 추가되었습니다. CLIP 인코더가 생성한 의미 임베딩은 이 Attention 모듈을 통해 처리됩니다.
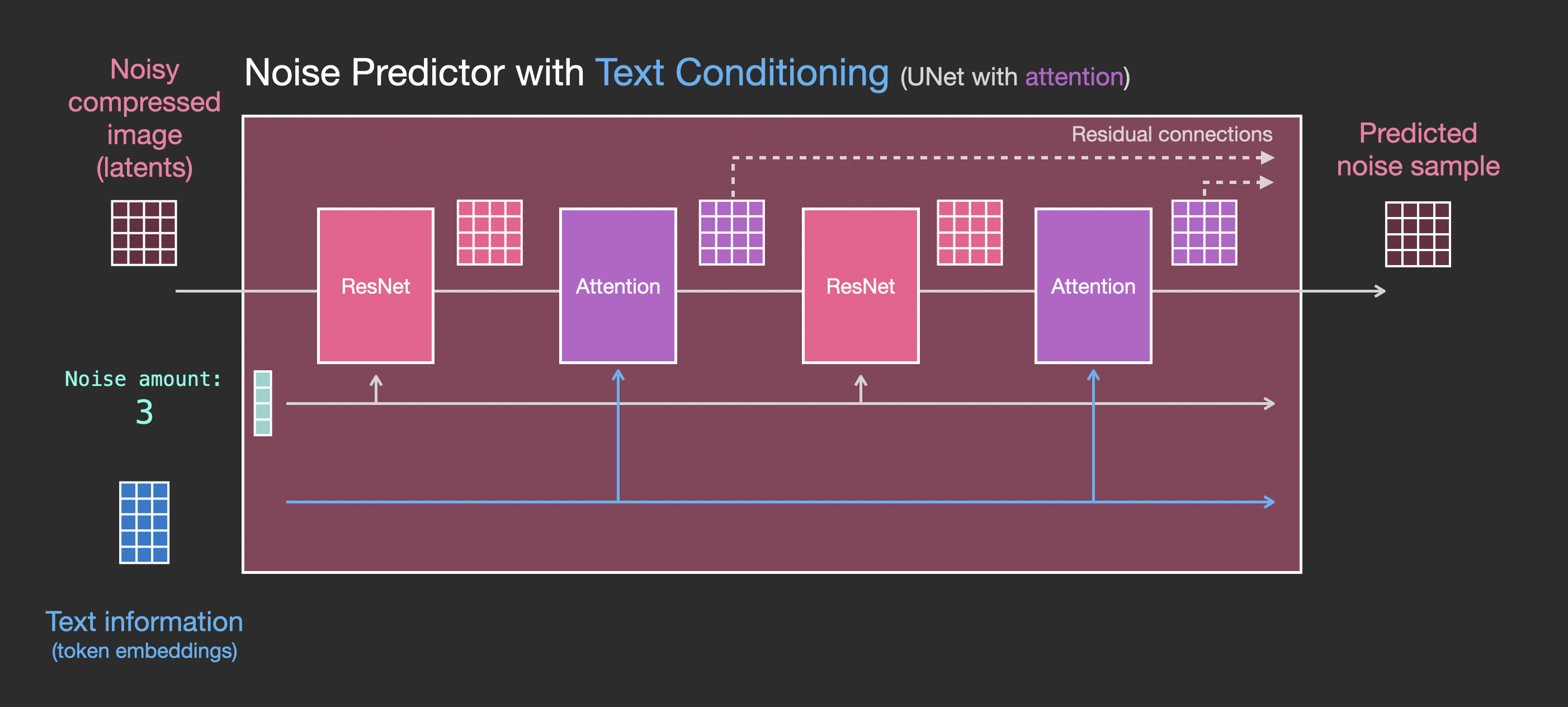
주목할 점은, ResNet 모듈이 텍스트를 직접 입력으로 사용하지 않고, Attention을 후처리 모듈로 사용한다는 것입니다. 이제 UNet는 이 방식을 통해 CLIP의 의미 정보를 성공적으로 활용할 수 있습니다. 이로써, 우리는 텍스트에서 이미지로 변환하는 작업을 성공적으로 완료할 수 있습니다.
5. Conclusion
여기까지 성공적으로 읽으셨다면, 먼저 이 세 편의 글, 총 만 여자에 달하는 긴 글을 모두 읽으신 것을 축하드립니다. 이 세 편의 글이 Stable Diffusion이 어떻게 작동하는지에 대한 기본적인 직관을 제공해드리길 바랍니다. 실제로는 이 외에도 많은 다른 모듈과 세부 사항들이 있지만, 이러한 기본 모듈의 작동 원리를 이해하고 나면, 추가적인 모듈들도 쉽게 이해하실 수 있을 것입니다.
마지막으로, 이 글의 내용을 간략히 요약하여 Stable Diffusion에 대한 이해 시리즈에 완벽한 마침표를 찍겠습니다:
- 의미 정보는 어디에서 오는가? CLIP 모델과 그 훈련 방법을 소개했습니다. 주로 매칭되는 이미지 쌍과 매칭되지 않는 이미지 쌍을 사용하여 CLIP 모델이 판단하게 하고, 그 결과에 따라 두 인코더의 파라미터를 업데이트합니다.
- 의미 정보는 어떻게 사용하는가? — 의미 정보가 없는 UNet을 살펴본 다음, 의미 정보를 사용하는 UNet으로 확장했습니다. 구체적으로는, 내부의 각각의 작은 ResNet 뒤에 어텐션 모듈을 추가하여 의미 정보를 처리합니다.
수정해야 할 부분이나 의문이 있으신 분들은 메일로 연락 주시길 바랍니다.